※ 본 내용은 Coursera, Machine Learning - Andrew Ng 강의, 강의자료를 바탕으로 작성하였습니다.
<Anomaly Detection>
Anomaly Detection은 비정상적인 데이터를 검출해내는 unsupervised learning 알고리즘이다.
(이후에 살펴보겠지만, training에 y가 사용되지 않는다.)

예를 들어 위와 같이 데이터(un-labeled)가 주어졌을 때, 우측하단의 anomaly로 표현된 데이터는 일반적인 데이터의 분포와 일치하지 않는 것을 확인할 수 있는데, 이를 anomlay detection으로 검출할 수 있다.
트레이닝 데이터로 feature에 대한 가우시안 분포를 찾고, p($ X_{test}$)가 임의의 값 $ \varepsilon $보다 작으면 anomaly로 판단시키는 방식이다.
- 사기 검출
- 불량 검사
등에 이용된다.
- Algorithm
앞서 말했듯, training 데이터로 가우시안 분포의 파라미터인 $ \mu$와 $ \sigma$를 학습한다.(각각의 feature에 대해.)
※ 가우시안 분포
-> pdf가 다음과 같은 분포를 따름.
$p = \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} $

이 후 최종의사 결정은 $ p(x) $의 값과 임의로 정한 $ \varepsilon $의 값을 비교하여 결정한다.
어떠한 데이터 $ x$에 대해 $ p(x)$는 다음과 같이 계산한다.
$ \prod_{j=1}^{n}{p(x;\mu_j,\sigma_j^2)} $,
즉, 각 feature에 대해 train을 통해 학습한 가우시안 분포의 파리미터와, 그를 바탕으로 계산한 pdf 값들의 곱을 계산한다.
알고리즘을 정리하면 다음과 같다.

*step2에서 $ \sigma$의 학습 시 m으로 나누는데, 통계학에서는 m-1으로 나누기도 한다.
약간의 차이가 있지만 주로 m이 큰 머신러닝에서는 문제가 되지 않고, m으로 나누는게 일반적이라고 한다.
- 성능 평가
기본적으로 모델의 학습에는 y set이 사용되지 않는 unsupervised learning이지만,
알고리즘을 테스트하는 것에는 y set을 사용한다.

다른 supervised learning과 같이 cross validation set과 test set을 추가로 이용한다. 두 데이터 셋에는 y label이 포함된다.
실제 데이터를 가정한 예시는 다음과 같다.

10000개의 정상 데이터와 20개의 비정상 데이터가 있다고 할 경우 ①로 표시된 것과 같이 분류하면 된다.
training 데이터에는 normal data만 사용된다.
-> 일반적인 분포를 찾고, 그에 벗어나는 것을 찾는 것이 목적이므로 normal 데이터만 학습시키는 것이다.
(anomalous한 데이터가 조금은 포함되어도 괜찮다.)
②와 같이 사용하는 경우도 있지만 권장하지 않는다.
Cross Validation set을 이용하여 $ \varepsilon $의 값을 조정해갈 수 있고,
최종적으로 test set을 통해 모델의 성능을 평가해볼 수 있다.
anomaly detection의 결과는 skewed된 데이터가 나오기 때문에 accuracay가 아니라,
precision, Recall을 이용한 F1 score를 통해 판단해야 한다.
- Anomaly Detection vs Supervised Learning
F1 score를 적용하는 것을 보고 supervised learning을 통해한 작업과 유사한 작업을 한다는 것을 알 수 있을 것이다.
그렇다면 두 알고리즘 중 어떤 알고리즘을 선택해야할까?
결과적으로 정리하면 y = 1(anomaly)의 데이터가 많이 없다면 anomaly detection을 적용하는 것이 좋고,
데이터가 충분하여 y=1인 경우에 대한 데이터도 꽤 있다면 supervised learning을 적용하는 것이 좋다.
*강의에서는 anomaly 데이터의 수가 0~20개인 경우 보통 anomaly detection을 적용한다고 한다.
y=1에 대한 데이터가 충분하지 않아도 y=0에 대한 데이터만 있다면 anomaly detection을 위한 일반적인 데이터의 분포를 학습할 수 있지만, supervised learning에서는 y=0과 y=1을 구분하기 위한 충분한 특징을 학습할 수 없기 때문이다.
- feature 선택, 처리
알고리즘을 보면 알 수 있듯이, feature로 주어지는 데이터가 정규분포를 따를 수록 좋은 성능을 보일 것이다.
(1) 변환

따라서 위 그림의 밑 예시 처럼 가우시안 분포를 따르지 않는 변수가 있다면, 해당 변수를 변환하여 새로운 변수로 매핑하는 방법을 취한다. 에를 들어, log를 취하거나 루트를 취하는 등의 방식이 있다.
(2) 조합하여 생성
상관관계가 있는 두 변수를 조합하여 새로운 변수로 생성해야 되는 경우도 있다.

data center의 컴퓨터들에 대해 위와 같은 feature가 주어진다고 하자.
직관적으로도 알 수 있듯이, CPU의 load와 network traffic 는 비례한다.
위 feature를 이용하여 detection을 수행하면, CPU load 적당히 높은 것은 크게 문제가 되지 않을 것이다.(detect 되지 않음)
그러나 이때 network traffic이 거의 없었다면 CPU 의 load가 높은 경우는 detect되었어야 하는 경우이다.(ex)무한 loop에 걸림)
각각의 변수를 따로 보게되면 anomly지만 detection에 실패하게 되는 것이다.
위 그림의 $ x_5$와 같이 두 변수를 조합하여 새로운 변수를 만드는 것을 통해 해결할 수 있다.
즉, 상관관계가 있는 변수간에는 조합을 통해 새로운 변수를 생성해주는 것이 좋다.
- Multivarivate Gaussian Distribution
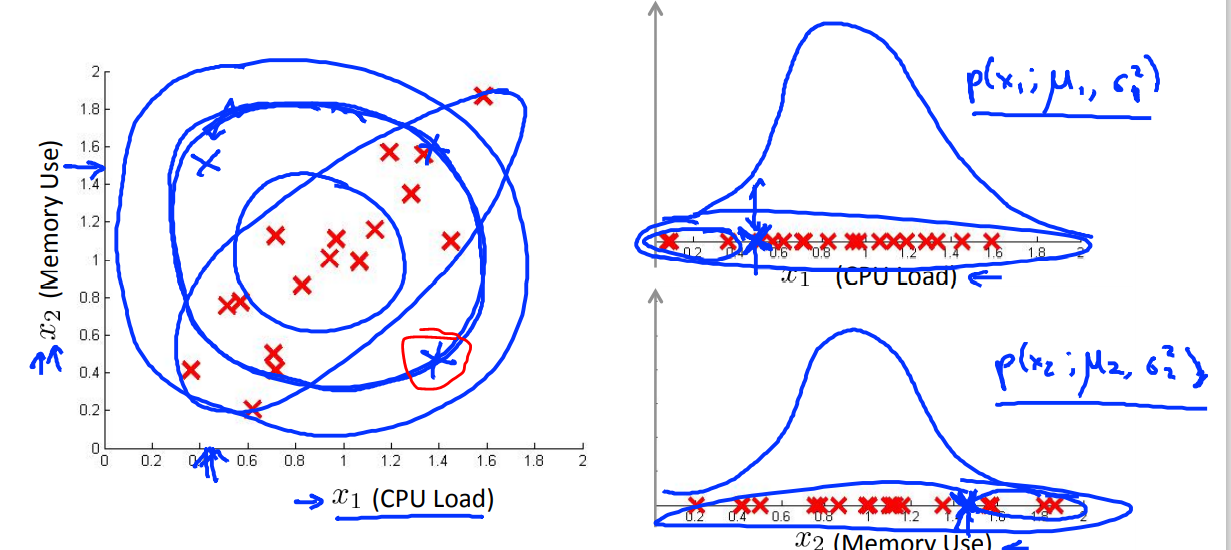
위와 같이 비례관계인 두 개의 feature가 있다면 각각의 feature의 분포를 이용하면 빨간색 원으로 표시한 데이터는 일반적인 분포와 다름에도 불구하고 anomly로 검출되지 않을 것이다.
좌측의 그래프에 타원으로 표시된 영역을 train해야 하지만, 등고선으로 표시된 영역대로 p를 학습하게 된다.
*이전의 data center의 CPU load와 traffic간을 조합하여 해결하는 것과 같은 문제이다.
두 개의 방법이 모두 이용 가능하다.->선택에 대해서는 마지막에 다룸
이러한 문제를 Multivariate Gaussian 분포를 이용하면 해결할 수 있다.
Multivariate Gaussain Distribution을 살펴보면 다음과 같다.

pdf는 위와 같이 계산하고, parameter로는 $ \mu$와 $ \sum $가 필요하다.
각각 n차원의 벡터와 nXn크기의 행렬이다.
(각 feature의 평균을 계산한 벡터와 covariance matrix)





$ \sum $ parameter의 변화에 따라 분포가 어떻게 나타나는지 알아볼 수 있다.
앞서 설명했던 문제는 예시 - 3과 같은 분포를 통해 해결할 수 있을 것이다.

참고로, 축에 평행한 features로 이뤄진 model의 경우, 어떠한 모델을 사용해도 실제로는 동일한 결과가 나온다.
(mulivariate model에서도 대각 행렬만 나옴, 나머지 = 0)
*증명 생략
- Original model vs Multivariate Gaussian Model
상관관계가 있는 변수의 경우,
(1) features의 조합으로 생성한 feature를 이용한, original 모델을 사용하는 방법
(2) multivariate 모델을 사용하는 방법
두 가지 방법이 있었는데, 두 방법 중에는 어떤 방법을 어떨 때 선택해야 할까.

방법(1) -
장 : 새로운 변수를 생성하는 방법은 m이 클 때 계산적인 측면에서 저렴하다.
단 : 그러나, feature를 어떻게 조합할지 직접 고려해야 한다.
방법(2) -
장 : 자동으로 feature간의 상관관계를 고려한다.
단 : m이 클 경우 계산이 expensive하다.(수식에 역행렬 계산이 있음), 또한 m>n인 경우 아예 계산이 불가능하다.
(또 다른 singular한 경우. ex) linear한 관계인 변수가 있다면 적용불가, 하나 삭제하면 적용할 수 있음)
'머신러닝 > Machine Learning(Ng)' 카테고리의 다른 글
| [10주차] Large Scale Machine Learning (0) | 2021.08.26 |
|---|---|
| [9주차 - 2] Recommender System (0) | 2021.08.24 |
| [8주차 - 2] Dimensionality Reduction, PCA (0) | 2021.08.22 |
| [8주차 - 1] Clustering, K-means algorithm (0) | 2021.08.21 |
| [7주차] Support Vector Machine (0) | 2021.08.19 |