※ 본 내용은 stanford에서 제공하는 cs231n 강의, 강의자료를 바탕으로 작성하였습니다.
Lecture 12에서는 CNN 동작을 이해하기 위한 visualizing을 다루고 있다.
- Visualizaing Filters

먼저 train된 모델들을 불러와 첫번째 layer의 필터를 시각화한 결과이다.
Edge나 line등 비교적 직관적인 feature를 detection하고 있는 것을 확인할 수 있다.
이전 강의에서도 다뤘듯 깊은 layer일수록 복잡한 특징에 response하고, 따라서 이후의 layers는 시각화하더라도 interpretable하지 않은 결과를 제공한다.
그러나 각각의 layers, weight가 어떻게 동작하고 있는지는 시각화할 수 있다.
먼저 AlexNet의 가장 마지막 FC layer가 어떻게 동작하는지 살펴보자.

앞선 강의에서 pixel값을 바탕으로 KNN을 classification에 이용하는 것은 비효율적일 뿐만 아니라, 정확하지 않은 것을 확인할 수 있었다.
그러나 마지막 FC layer의 출력값(4096-dim vector)을 기준으로 KNN을 수행하면 꽤 정확한 결과를 보인다.
(각 이미지마다 마지막의 layer의 출력값을 저장해두고, 해당 값을 기준으로 classification을 수행하는 방법)

위 이미지는 Mnist datasets에 대한 layer FC layer의 출력결과에 t-SNE라는 dimensinality reduction 기법을 적용한 결과이다.
10개의 군집으로 구분되는 것을 확인할 수 있다.
- Visualizing Activations

Activations를 시각화하여 각 filter가 어떠한 역할을 수행하는지 짐작해볼 수 있다.
위 이미지는 conv5의 activation을 시각화한 결과로, 128개 chnnel에 대해 각각 13x13 grayscale 이미지로 출력한 결과이다.
대부분 해석하기 어려운 결과를 보이지만, 초록 사각형으로 표시된 부분은 사람의 얼굴 부분에 대해 높은 activations를 보인다.
해당 filter는 사람의 얼굴을 감지하는 등의 역할을 수행하는 것으로 예상할 수 있다.

반대로 여러 이미지를 model에 input으로 주고, 임의의 filter에 대한 activations를 기록한 후 그 값이 컸던 이미지를 살펴보는 방법으로 그 filter의 동작을 예상해보는 방법도 있다.
임의의 filter에 대한 activation이 컸던 이미지들을 정리해둔 결과이다.
첫 행의 filter는 원을 감지하는 등의 기능을 수행할 것이고, 4번째 행의 filter는 글자를 감지하는 등의 기능을 수행할 것이라는 것을 예상해볼 수 있다.

나아가서, 모델이 이미지의 어떠한 영역을 보고 결정을 내렸는지 파악하는 것도 가능하다.
오른쪽의 결과는 이미지의 일부 영역을 masking한 후, 해당 영역을 가렸을 때 classification probabiliy가 어떻게 변화하는지 출력한 결과이다.
실제 해당 객체가 있는 영역일수록 probabilty가 낮아지는 것을 보며, 모델이 실제 객체를 인식하고 classification을 수행한 것임을 알 수 있다.

같은 원리로 image pixel에 대한 score의 미분값을 계산해보아도, 어떠한 pixel이 classification에 큰 영향을 미쳤는지 알 수 있다.
실제 개가 있는 영역이 잘 감지된 것을 확인할 수 있다.
이러한 방법을 segmentation에 응용하기도 한다.

이미지가 아니라 특정 filter의 activation값을 기준으로 미분을 수행하여 해당 filter의 출력엔 이미지의 어느 부분이 영향을 끼쳤는지 파악하는 것도 가능하다.
앞서 임의의 filter에 대한 activation이 큰 값을 보였던 이미지를 정리해두었던 자료에 대해, 그 filter의 actavtion에 대해 미분을 수행한 결과는 위와 같다.
예상한 것과 같이 첫번째 필터는 동그라미, 4번째 필터는 글자의 형태에 크게 영향을 받는다.
- Gradient Ascent
Train 시 optimization을 수행하기 위해서는 gradient descent 알고리즘을 통해 loss를 최소화하는 방향으로 weight를 학습시켰다면,
gradient ascent를 이용하여 어떠한 filter의 activation score를 최대화하는 방향으로 image를 학습시키는 것도 가능하다.

특정 class에 대한 score를 최대화하는 방향으로 임의의 noize로 제공된 이미지가 gradient descent를 통해 변경하면, 위와 같이 해당 calss의 형태가 보이게 된다.
뒤의 regularization term은 특정 pixel의 값을 통해 score가 커지게 하는 것을 방지하여 이미지가 실제 이미지와 유사하게 되도록 조정하는 역할을 한다.
결과이미지에 값이 낮은 pixel은 0으로 처리하는 등의 추가적인 작업을 수행하여 조금 더 사실적으로 만드는 것도 가능하다.
- Fooling Images / Adversarial Examples
Gradient ascent를 이용하여 어떠한 이미지가 다른 class에 대한 score가 커지도록 작업하는 것도 가능하다.

코끼리 이미지를 koala class에 대한 score가 크도록, schooner이미지를 iPod class에 대한 score가 커지도록 조정한 결과이다.
실제 이미지와 크게 다르지 않지만, 모델은 잘못인식하게 된다.
이에 대해서는 추가적인 하나의 강의를 통해 다룬다고 한다. (Lecture 16)
- DeepDream
실용적이기 보다는 실험적이고 재미를 위한 실험이다.
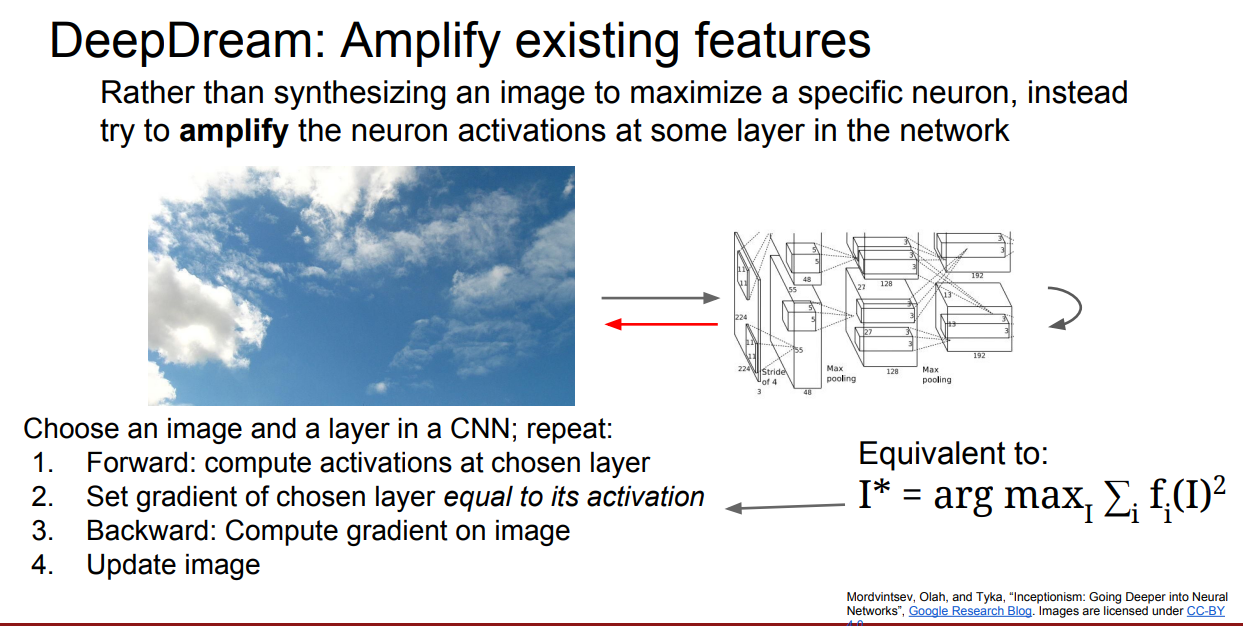
특정 뉴런보다는 어떠한 layer에서의 activations를 최대화하도록 gradeient ascent를 적용하면 해당 layer에서 response하던 features가 이미지에 나타나게 된다는 원리이다.

어떠한 layer를 선택하느냐에 따라 위와 같은 결과들이 생성된다.
- Feature Inversion / Texture Synthesis

Feature Inversion을 통해 이미지에서 특정 feature에 match하는 부분들을 강조할 수 있다.
어떠한 이미지에 대한 한 layer에서의 feature vector와 원본 이미지가 주어지면, 새로운 이미지와 해당 feature vector의 l2 distance를 최소화하면서 이미지가 자연스럽게 보이도록 학습시키는 방법이다.

결과는 위와 같다.
깊은 층의 feature에 대해 적용할 수록 원본이미지와 달라지는 것을 확인할 수 있다.
이는 앞 layer에서는 raw pixel 에서 정보를 많이 보존되지만, 깊어질수록 색이나 질감같은 deatail보다는 semantic한 정보를 이용한다는 것을 의미한다.
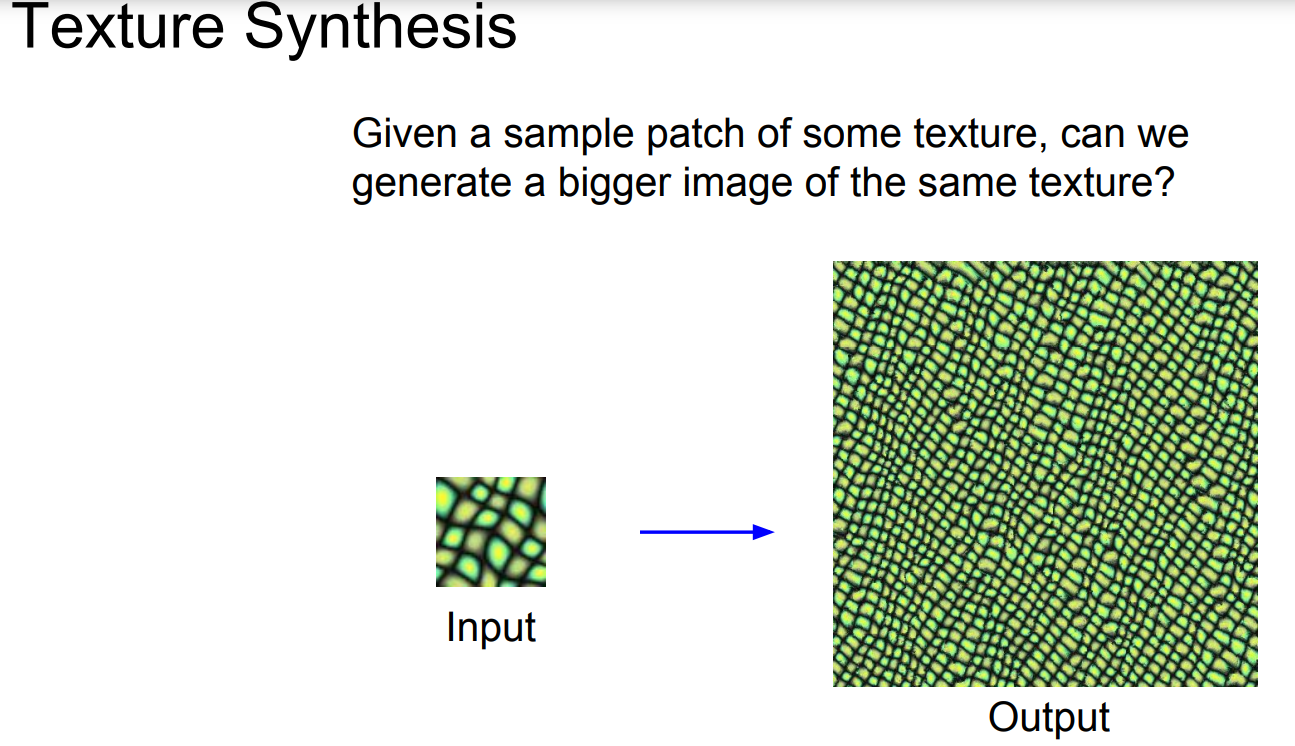
Texture 정보가 담긴 patch가 주어졌을 때, texture를 유지하는 더 큰 이미지를 생성하는 task가 Texture Synthesis이다.
위 output은 KNN을 이용한 결과로, KNN을 통해서도 어느정도 구현이 가능하지만 복잡한 패턴일수록 한계가 존재했다.
해당 task에 대해서도 딥러닝을 통해 한계를 극복할 수 있었다.

각 layer마다 CxHxW tensor를 출력할 것이고, 이때 각 위치별로 C 차원 벡터 2개에 대한 outer product를 계산하여 CxC 크기의 matrix를 생성할 수 있다.
(co-occurence 정보를 계산하는 것, co-variance matrix를 사용하지 않은 이유는 outer product의 계산상 이점 때문)
그러한 matrix의 모든 위치 조합에 대한 결과를 평균낸 결과가 Gram Matrix이다.

위와 같은 총 9계의 단계를 통해 딥러닝을 통한 texture sysnthesis가 가능하다.
조금 더 단계를 통합하면 다음과 같이 그 동작을 정리할 수 있다.
(1) 주어진 image patch에 대해 모든 layer에서 Gram Matrix를 계산
(2) Random noise 이미지에 대해 Gram Matrix를 계산하고 기존 image patch의 gram matrix와 비교
(3) 그 차이를 loss로 계산하여 optimization 수행

위와 같이 꽤 괜찮은 결과를 보인다.
(Layer가 나눠진 이유는 비교를 위해 각 layer별 Gram Matrix의 차이를 loss로 실험을 진행했기 때문, 실제로는 모든 layer의 Gram Matrix 차이의 합을 loss로 사용)
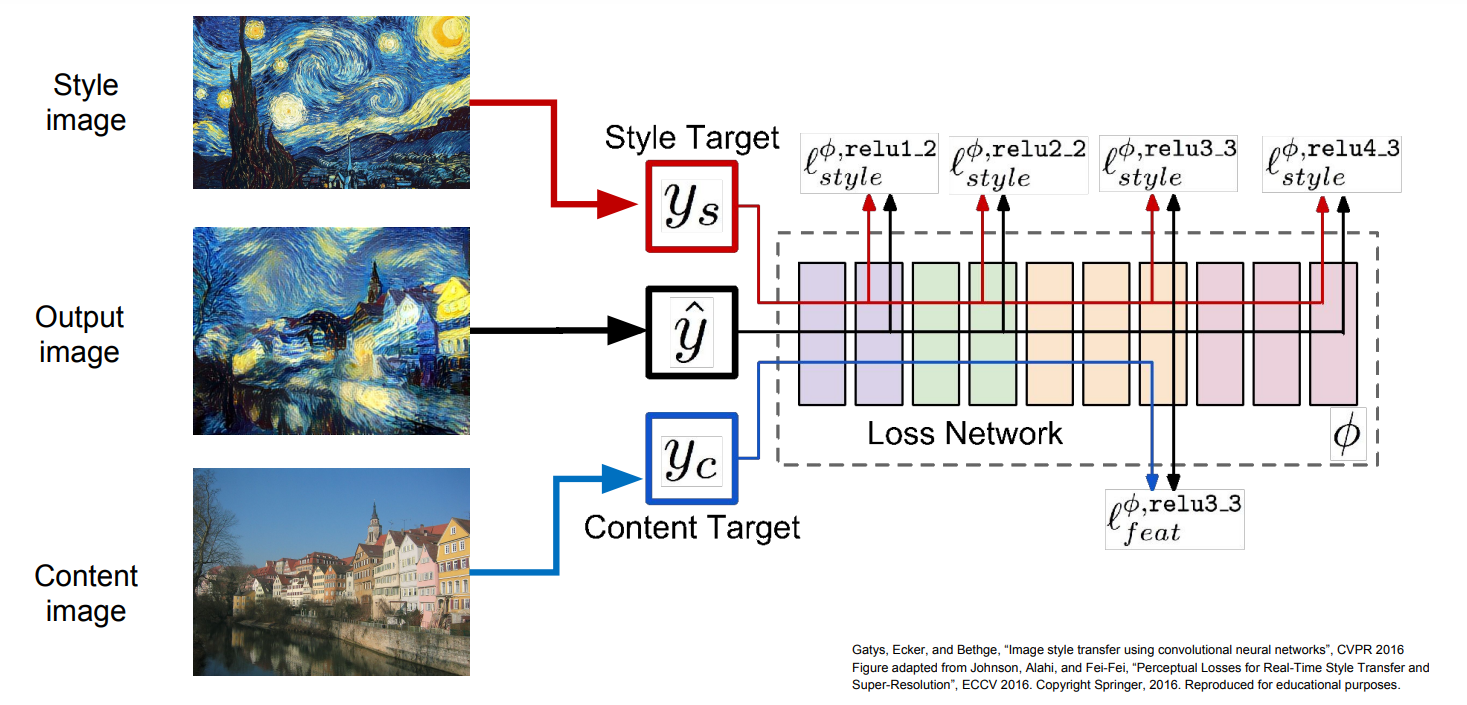
Content image에 대한 feature reconstruction(feature inversion)과 texture synthesis를 결합하여 content image를 해당 texture style로 변환하는 것도 가능하다.
위 그림에 나와있듯이 feature reconstruction을 위한 loss와 texture synthesis에 대한 loss를 모두 계산하는 방법으로 구현이 가능하다.
그러나 위 방법은 각 image 마다 수많은 forward/backward 연산을 반복해야 되기 때문에 실용적이지 않다.
Fast Style Transfer
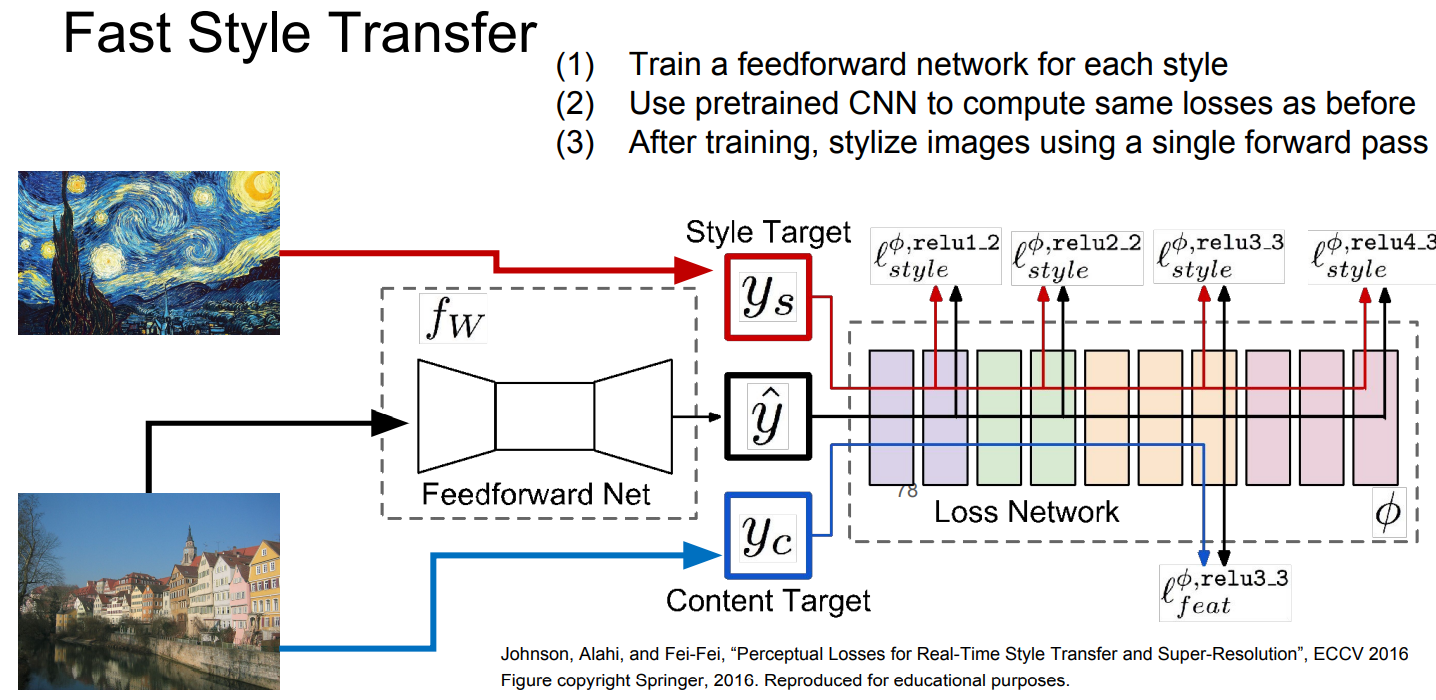
따라서 'Fast Style Transfer'에서는 각 style 별로 새로운 feedforward Network를 학습시켜, 해당 feedforward network만 거치면 학습된 style로 transfer가 가능하도록 한다.
'Computer Vision > cs231n' 카테고리의 다른 글
| [Lec 14] Reinforcement Learning (0) | 2022.01.29 |
|---|---|
| [Lec 13] Generative Models (0) | 2022.01.26 |
| [Lec 11] Detection and Segmentation (0) | 2022.01.24 |
| [Assignment 2] Convolution 역전파, Spatial Batch Normalization (1) | 2022.01.21 |
| [Assignment 2] Batch Normalization, 역전파 (0) | 2022.01.20 |