※ 본 내용은 Coursera, Machine Learning - Andrew Ng 강의, 강의자료를 바탕으로 작성하였습니다.
<Neural Network>
- Non-linear classification
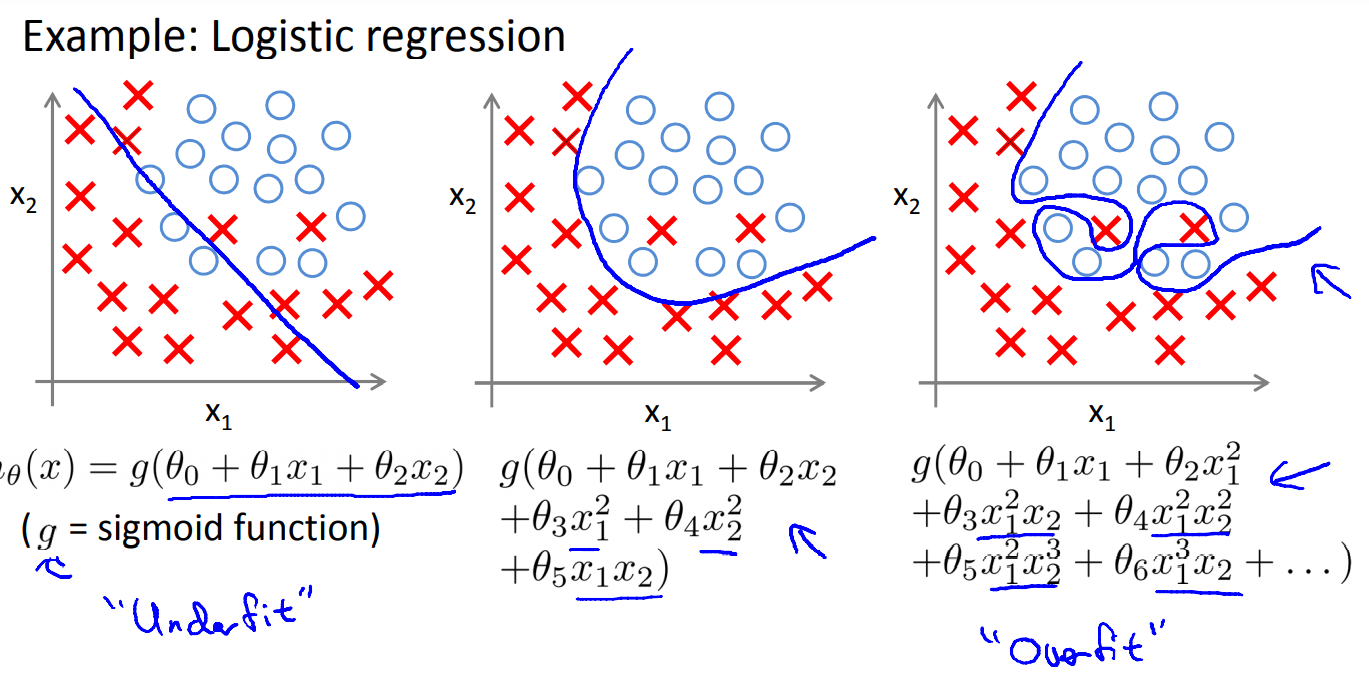
데이터를 항상 linear한 모델로는 설명할 수 없다.
이를 해결하기 위해 앞서 polynomial regression과 같은 방법을 이용하여 non-linear한 classfication을 수행하였다.

그러나 이러한 방식으로는 n개의 feature를 통해 대략 이차항의 조합만 추가하여도, $ \frac{n^{2}}{2}$개에 비례하는 새로운 feature를 만들게 된다.
3차항 이상의 조합까지 추가하면 feature의 수가 굉장히 많아져, 연산이 사실상 불가능하거나 지나치게 오래걸리게 된다.

또한 이미지 처리의 경우 각 pixel 위치마다 feature로 처리하면,
간단하게 50x50 크기의 이미지만 처리하려해도 1차항으로 2500개의 feature가 나온다.(gray scale)
여기에 이차항 조합까지만 추가하려 해도 3 million 개의 feature가 나오게 된다.
- Neural Networks
따라서 Neural Network는 이러한 문제를 해결할 수 있는 non-linear 모델으로,
실제 뇌의 뉴런 세포들의 동작을 mimic 하는 방식으로 학습하는 알고리즘이다.
- 뉴럴 네트워크 구조

layer구조를 이루어, input layer와 output layer 그리고 그 사이의 hidden layers로 구성되어 있다.
- input layer와 output layer는 이름 그대로 입력과 출력값을 의미하고, 그 외의 layer를 모두 hidden layer라고 한다.
- 노란색으로 표시된 unit 들이 하나의 뉴런에 대응된다고 보면 된다.
각 뉴런에서 하는 일은 logisitic regression에서 하는 일과 동일하다. 즉 sigmoid function의 값을 계산하는데, 뉴럴 네트워크에서는 activation이라고 표현한다. 위 그림에서 $ a$로 표현된다.
* $ a_{i}^{(j)} $는 j layer에서 i번째 unit의 activation을 의미한다.
* bias unit은 항상 1의 값을 갖는 값으로, 계층의 0번째 activation으로 보면 된다. 그림에서는 생략하는 경우가 많다.
- 내부 동작(계산)
각 activation의 계산 과정을 자세히 살펴보면 다음과 같다.

* $ \Theta^{j} $는 matrix of weights를 의미한다. (뉴럴 네트워크에서 각 파라미터를 weights, 가중치로 표현한다.)
파라미터의 결정에 대해서는 이후에 다룬다고 한다.
어쨌든 위 식을 계산하려면, 슬라이드의 밑에 나와있는 것처럼 $ \Theta $는 $s_{j+1} \times (s{_j}+1) $ 크기의 matrix가 된다. +1은 bais unit에 의한 것이다.
식이 조금 복잡하기 때문에 다음과 z를 다음과 같이 정의하여 나타낼 수도 있다.
$ z{_{k}}^{j} = \Theta {_{k,0}}^{(j-1)}x{_0} + \Theta {_{k,1}}^{(j-1)}x{_1} + ... + \Theta {_{k,n}}^{(j-1)}x{_n}, $
vectorization을 적용하면 다음과 같다. input layer는 $ a^{(1)} $으로 취급하면 된다.
$ z^{j} = \Theta ^{j-1}a^{j-1} $
최종적으로
$ a^{j} = g(z^{(j)}) $
와 같이 나타낼 수 있다.
- 장점

위 그림과 같이 input layer를 가려본다면, layer 2를 input layer로 봐도 문제가 없다.
즉, Neural Network 구조에서는 임의로 feature를 생성하지 않아도,
계속해서 새로운 feature를 learning한다고 볼 수 있다.
- Simple Example
간단한 non-linear classification의 적용 예시는 다음과 같다.
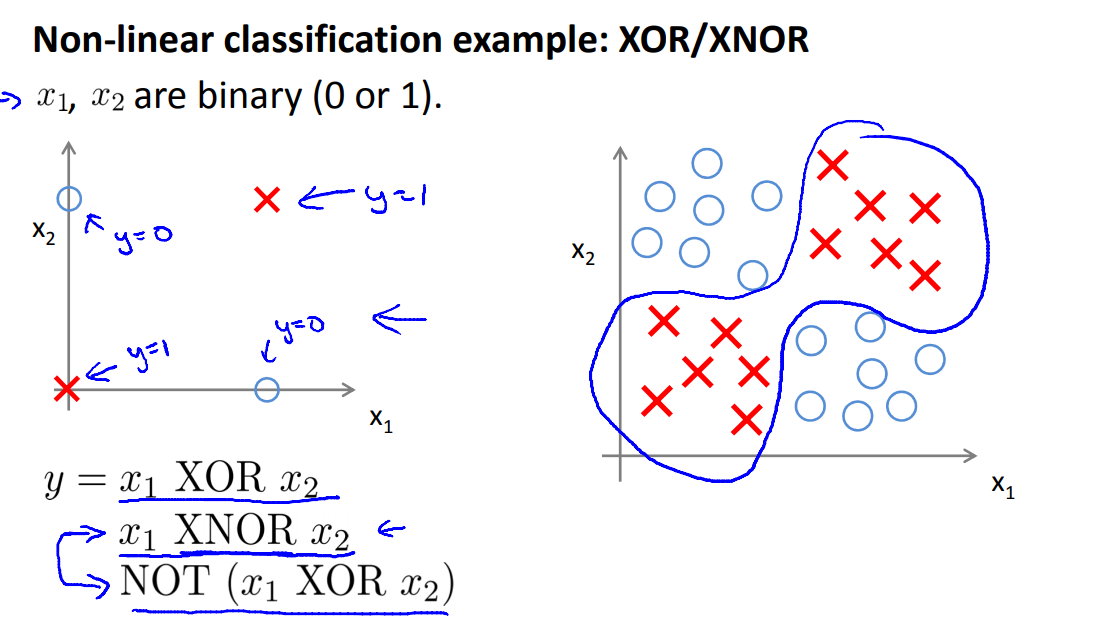
위와 같은 데이터를 분류하기 위해선, non-linear한 모델이 필요한 것을 알 수 있다.
참고로 x1 XNOR x2 연산을 통해 분류할 수 있다.

우선 AND 로직은 위와 같이 가중치를 설정하여 계산할 수 있다. truth table을 통해 쉽게 이해할 수 있다.

최종적으로 위와 같은 구조를 통해 XNOR을 구현할 수 있다.
(OR 등의 로직도 truth table을 통해 간단히 확인할 수 있으므로 생략)
이번 예시는 간단한 예시이지만, 이를 통해
뉴럴 네트워크의 구조를 잘 설계하여 복잡한 로직의 처리도 가능하다는 것을 알 수 있다.
- Multi-Class Classification

output layer의 unit을 1개가 아닌 여러개로 설저하고, output을 vector로 다루면 multi-class classification으로도 확장이 가능하다.
'머신러닝 > Machine Learning(Ng)' 카테고리의 다른 글
| [6주차 - 1] 모델 성능, Bias와 Variance (0) | 2021.08.16 |
|---|---|
| [5주차] Neural Network - 2 (0) | 2021.08.14 |
| [3주차-2] Regularization (0) | 2021.08.10 |
| [3주차- 1] Classification, Logistic Regression (0) | 2021.08.10 |
| [2주차] 다변수 선형 회귀, Normal Equation (0) | 2021.08.07 |