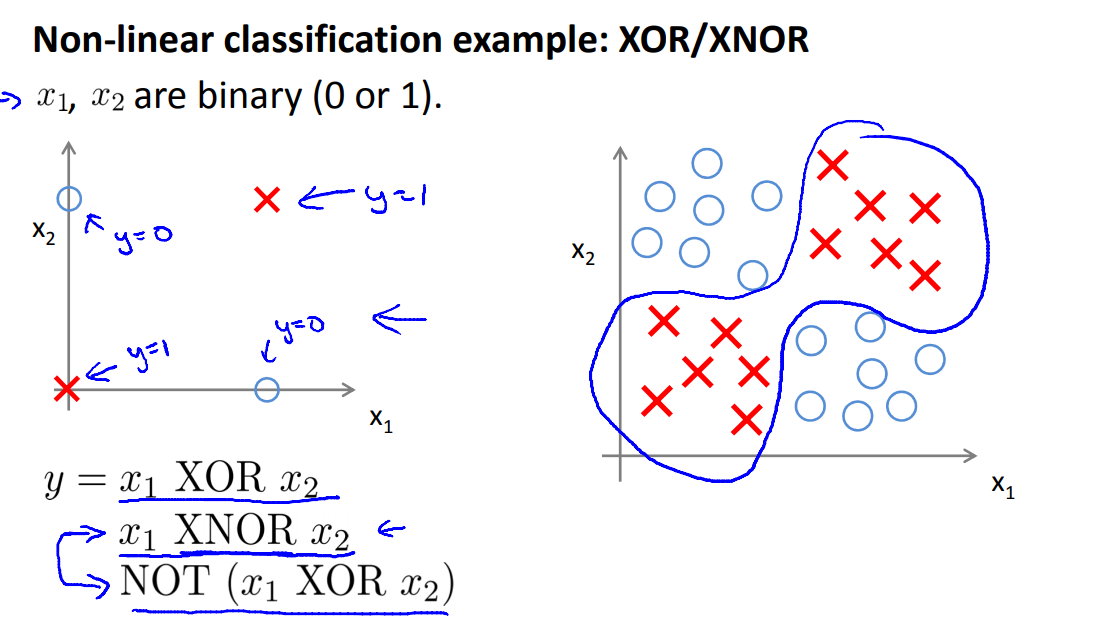
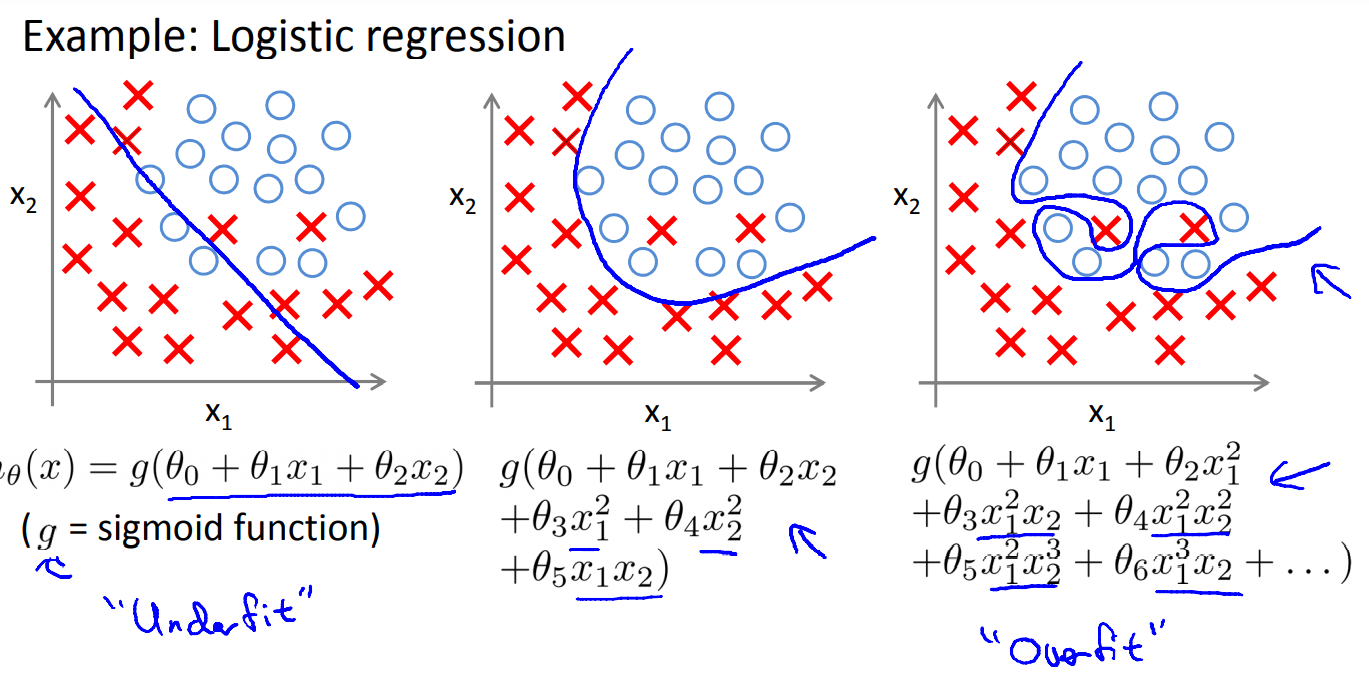
※ 본 내용은 Coursera, Machine Learning - Andrew Ng 강의, 강의자료를 바탕으로 작성하였습니다.
<성능과 diagnostic>
만약 학습시킨 모델이 새로운 데이터에 대해서 좋지 못한 성능을 보인다면 어떻게 해야할까?

위의 리스트와 같은 것들을 시도해볼 수 있을 것이다.
그러나 위 방법이 모든 경우에 성능을 향상 시키는 것은 아니고, 따라서 무작위하게 여러 방법들을 시도해보는 것은 비효율적이고 시간을 무의미하게 낭비할 가능성을 높인다.
따라서 적절한 diagnostic 을 이용해야한다.
한국말로 처방이란 뜻을 가진 단어답게, 현재 모델이 어떤 문제를 갖고 있고 어떠한 개선이 필요할지 확인하는 테스트이다.
<성능 평가와 Model Selection>
모델의 성능을 평가할 때는 training 데이터에 사용된 데이터로 계산된 cost function이 낮은 것만이 중요한게 아니라, 모델이 보지 못했던 데이터에 대한 예측력도 중요하다.
특정 데이터를 기준으로만 성능을 높이는 것을 over fitting을 유발하고, generalized 성능을 낮추기 때문이다.
따라서 주어진 데이터를 트레이닝에 사용될 데이터와 test에 사용될 데이터로 나누는 것이 일반적이다.(보통 7:3비율)
그러나 단순히 train/test set으로 나누게 되면 다시 test set으로 사용된 데이터를 기준으로 적합된 모델을 만들게 될 가능성이 크다.
그러한 문제를 막기 위해 train/cross validation/test 데이터셋으로 나누는 것이 좋다.(보통 6:2:2)
모델은 training data set을 이용해 학습시키고, cross validation data set을 이용하여 모델의 성능을 확인한 후, 마지막으로 test 데이터셋을 통해 최종적인 일반화 성능을 확인할 수 있다.

예를 들어, 위와 같은 경우에서 몇차항까지 feature로 사용해야 좋은 모델을 만들 수 있을지 결정하기 위한 과정은 다음과 같다.
1. 우선 training 데이터를 기준으로만 성능을 평가한다면 과적합을 방지할 수 없기때문에, train/validation/test data set으로 구분한다.
2. training data set을 이용하여 각 모델별로 파라미터를 학습시킨다.
3. 그렇게 학습된 모델별로 validation set에 대한 성능을 평가하고, 가장 좋은 성능을 보이는 모델을 선택한다.
4. 마지막으로 test data set을 통해 generalization error를 평가할 수 있다.
* 일반적으로 데이터가 충분하고 random하게 잘 구분지었다면, validation set에 대한 성능이 좋은 모델이 test set에 대한 성능도 좋게 된다.
* 성능 평가를 위해 사용하는 cost function에서는 regularization에 대해서는 고려하지 않는다. (즉 h와 y만 이용)
<Bias와 Variance 평가>
- Bias와 Variance
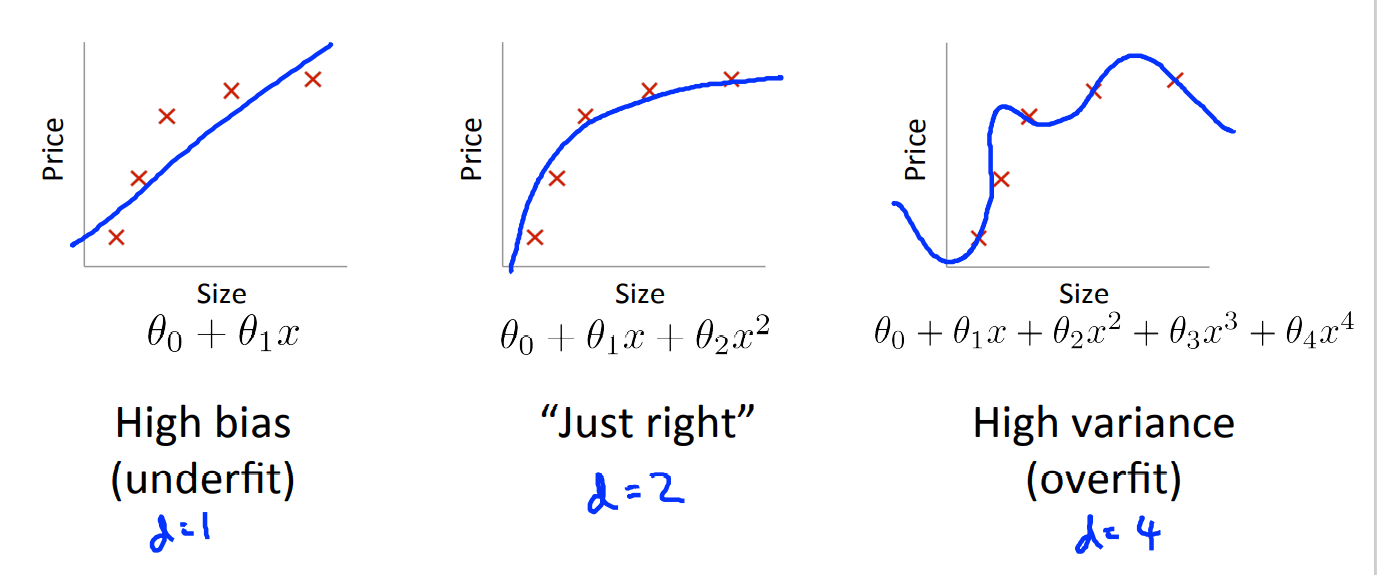
우선 Bias와 Variance의 의미는 다음과 같다.
High Bias : underfitting
High Variance : overfitting
(물론 별도의 수식이 있다.)

위의 그래프에서 빨간선은 training 데이터 셋에 대한 cost J 이고, 초록색은 CV data set에 대한 cost J이다.
(cost가 낮을 수록 좋은 예측 성능을 의미)
다항식의 차수를 추가할 수록, training set에 대한 설명력은 좋아지기 때문에(overfitting) 그에 대한 cost는 낮아진다.
반면 cv에 대한 cost는 차수가 낮을 때는 training과 동일하게 높다가(underfitting), 어느 정도 낮아진 후 과적합이 될수록 다시 향상되는 것을 확인할 수 있다.
다시 말해,
high bais인 경우, underfitting인 경우는 training data set과 cv data set 모두에 대해 예측 성능이 좋지 못하고,
high variance인 경우, overftting인 경우에는 training data set에 대한 성능은 좋지만 cv data set에 대한 성능은 좋지 못하다.
<Regularization과 bias/variance>
앞서 regularization 자체가 overfitting을 막기 위해 고려했던 작업인만큼 bias, variance 문제에서 중요하다.

위 그림과 같이 하나의 모델에서도 regularization parameter 람다를 크게하냐 작게하냐에 따라 overfitting과 underfitting 문제가 발생할 수 있다. 반대로 적당하게 조정하여 문제를 해결할 수도 있다.
- regularization parameter 선택
그렇다면 어떻게 적당한 크기의 람다를 선택해야될까? 단순히 앞에 정리했던 내용을 바탕으로 선택하면 된다.
여러 값의 람다에 대해 트레이닝시킨 모델들을 만들고, cv data set을 통해 성능을 확인해보고 가장 좋은 모델을 선택하면 된다. 이 후 test data set을 통해 일반화 성능도 확인할 수 있다.

람다를 x축, cost를 y축으로 놓고 그래프를 그리면 일반적으로 위와 같이 그려질 것이다.
<Learning Curves>
bias와 variance가 높은 경우 각각 traning에 데이터가 많아질수록 모델의 정확도가 변화하는 양상이 다르다.
- bias가 높은 경우

(1) training 데이터가 많아질수록 train error는 커진다.
(2) cv 셋에서 대한 error는 데이터가 많을 수록 작아진다.
(3) 그러나 둘 다 점진적으로 plat한 형태가 되고 결국 매우 비슷하게 된다. 이때의 error는 큰 값으로 볼 수 있다.(underfit 되어 있기 때문에)
- high variance 인 경우

(1) m이 커질 수록 train에 대한 오류가 커지긴 하지만 크지 않다.(overfitting)
(2) cv data set에 대한 오류는 m이 커질수록 작아지지만, train에 대한 오류에 비하면 큰 gap을 갖는다.
(3) m이 커질수록 그 gap은 작아진다.
위 두 내용을 통해 알 수 있는 점은 다음과 같다.
high bias 문제라면 데이터를 늘리는 것이 도움이 되지 않을 가능성이 크고,
high variance 문제라면 데이터를 늘리는 것이 도움될 가능성이 크다.
이러한 점을 알면 가장 처음에 말한 무의미한 시도를 줄일 수 있다.
<정리>
그렇다면 초반에 말한 해결책들이 어떤 경우에 쓰일 수 있는지 다시 보자.

어렵지 않게 이해할 수 있다.
< Neural Network의 경우? >
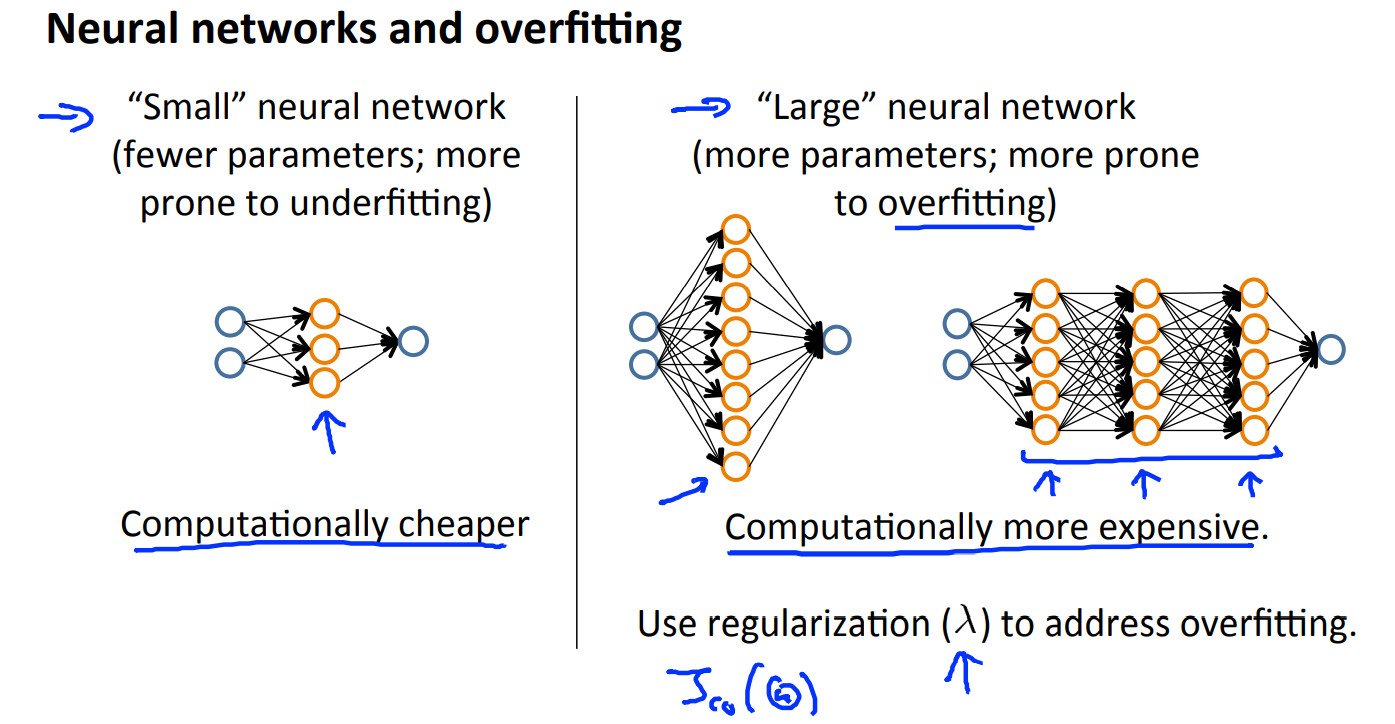
이번 강의에서 다룬 내용과, 뉴럴 네트워크에서 hidden layer가 새로운 변수를 만드는 것과 유사하다는 점을 고려하면 아래 내용 또한 자연스럽게 이해할 수 있다.
우선 NN 자체가 너무 작다면 underfitting에 취약하다. 직관적으로도 이해할 수 있고, parameter가 적으니 underfitting 될 가능성이 큰게 당연하다.
반대로 NN의 netwrok가 크다면 overfitting에 취약하다. 같은 원리로 이해할 수 있다.
따라서 Neural Netwrok에서는 다음과 같은 조치를 취할 수 있다.
(1) 다항식의 차수를 변화시켜가며 model selection을 했던 것을 hidden layer의 계층의 수를 변화시켜가며 동일하게 적용해볼 수 있다.
(2) regularization parameter를 조정하여 overfitting을 해결한다.
'머신러닝 > Machine Learning(Ng)' 카테고리의 다른 글
| [7주차] Support Vector Machine (0) | 2021.08.19 |
|---|---|
| [6주차 - 2] prioritizing what to do, error matrix (0) | 2021.08.18 |
| [5주차] Neural Network - 2 (0) | 2021.08.14 |
| [4주차] Neural Network (0) | 2021.08.11 |
| [3주차-2] Regularization (0) | 2021.08.10 |