※ 본 글은 '[도서]파이썬과 케라스로 배우는 강화학습' 및 '[유튜브]혁펜하임의 트이는 강화학습'을 학습하고 작성한 글입니다.
이제 본격적으로 강화학습 알고리즘 알고리즘인 SARSA와 Q-Learning 에 대해 살펴보자.
1. SARSA
먼저 앞서 살펴 본 시간차 예측에서, 가치함수 업데이트 수식을 살펴보자.
V(s)←V(s)+α(Rt+1+γV(St+1−V(s))
시간차 예측 가치함수 업데이트 수식
SARSA는 기본적으로 위 수식을 기반으로 한다.
여기에서 아래와 같은 2가지 특징을 갖는다.
(1) Q 함수를 이용한다.
(2) 정책은 ϵ - greedy 정책을 이용한다.
1. (1) SARSA 학습 과정
위에서 살펴보았듯, SARSA는 Q 함수, 행동 가치함수를 통해 학습한다.
이를 수식으로 나타내면 다음과 같다.
Q(s,a)←Q(s,a)+α(Rt+1+γQ(st+1,at+1)−Q(s,a))
SARSA 큐함수 업데이트 수식
업데이트에 사용되는 값이 S,A,R,St+1,Rt+1 라서, SARSA 알고리즘이라고 부른다.
그런데 여기서, 행동은 어떤 행동을 선택하게 될 까?
즉, 정책이 무엇인지 궁금하다.
앞서 말했듯이 ϵ - greedy 정책을 이용한다.
1. (2) ϵ - greedy 정책
먼저 greedy 부터 살펴보자. 가장 좋은 것을 고르겠다는 의미이다.
즉, 기본적으로는 Q(s, a)가 가장 큰 행동을 취하면 된다.
다음으로 ϵ의 개념을 살펴보기 전에 먼저 다음 예시를 보자.

학습 초반 Q 함수는 랜덤하고 균등하게 분포되어 있을 것이다.
이 과정에서 우연히 위와 같은 코스를 반복해서 간다면, s = (0, 0)에서 Q(s, a)를 최대화하는 행동은 '아래로 이동'일 것이다.
이렇게 한번 설정이 되어 버리면, greedy 정책에 의해 계속해서 이 길만 선택하게 된다.
하지만 실제로 최적의 루트는 '오른쪽으로 이동'하는 것이다.
이런 문제를 예방하기 위해, ϵ의 개념이 등장한다.
기본적으로는 greedy 하게 이동하되, ϵ의 확률만큼은 랜덤하게 움직이는 것이 ϵ -greedy 정책이다.
이때 랜덤하게 움직이는 것을 '탐험' 이라고 하고, 최적의 정책을 찾기 위해 중요하다.
1. (3) 의사코드
SARSA 학습 과정을 간단하게 의사 코드로 표현해보자.
action = get_action(state) #epsilon greedy 기반 행동 추출
cur_q = q_table[state][action]
next_state, reward = do(state, action) # 환경에 의해 결정
next_action = get_action(next_state)
next_q = q_table[next_state][next_action]
td = reward + discount_factor*next_q - cur_q
q_table[state][action] = q_table[state][action] + step_size*tdQ(s,a)←Q(s,a)+α(Rt+1+γQ(st+1,at+1)−Q(s,a)
SARSA 큐함수 업데이트 수식
기본적으로는 위 수식을 코드로 표현한 것이다.
next_state가 환경에 의해 달라질 수 있다는 점과,
next_action을 고를 때에도 ϵ-greedy 정책에 기반한다는 점에만 유의하면 된다.
2. 큐러닝, Q-Learning
2. (1) 큐러닝 업데이트 수식
큐러닝 역시 시간차 예측 기반의 알고리즘이고, SARSA와 거의 유사하지만 다음의 차이가 있다.
현재 상태에서는 ϵ-greedy 정책을 통해 행동을 선택하고, 다음 상태에서는 가장 큰 큐 함수를 이용한다.
SARSA에서는 at+1 또한 ϵ-greedy 정책을 사용하여 현재의 가치 함수를 업데이트했다.
Q-Learning에서는 그냥 가장 큰 Q(st+1,at+1을 사용하여 현재의 가치 함수를 업데이트한다.
수식으로 비교하면 다음과 같다.
Q(s,a)←Q(s,a)+α(Rt+1+γQ(st+1,at+1)−Q(s,a)
SARSA 큐함수 업데이트 수식
Q(s,a)←Q(s,a)+α(Rt+1+γmaxa′Q(st+1,a′)−Q(s,a)
큐러닝 큐함수 업데이트 수식
(※ 여기서 maxa′Q(st+1,a′)는, a'을 선택하겠다는 것이 아니라, 그냥 가장 큰 Q 함수를 그대로 사용하는 것이다.)
수식 상으로는 큰 차이는 없어보이지만,
이 간단한 차이로 인해, SARSA는 on-policy, 큐러닝은 off-policy가 되고, 꽤나 큰 차이를 불러온다.
이에 대한 내용은 뒤에서 다시 정리하고, 큐러닝 학습 의사코드를 먼저 살펴보자.
2. (2) 큐러닝 의사코드
action = get_action(state) #epsilon greedy 기반 행동 추출
cur_q = q_table[state][action]
next_state, reward = do(state, action) # 환경에 의해 결정
next_q = max(q_table[next_state]) # next_action을 굳이 뽑을 필요가 없다.
td = reward + discount_factor*next_q - cur_q
q_table[state][action] = q_table[state][action] + step_size*td수식도 그렇듯, 의사코드 또한 거의 비슷하다.
차이가 발생하는 부분은 next_q를 구하는 과정이다.
SARSA에서는 next_action을 ϵ-greey 정책으로 선택한 후, next_state와 next_action 의 Q 함수를 next_q 로 이용했다.
큐러닝에서는 next_action을 추출하는 과정이 없다. next_state 만 알면, next_state에 대한 Q 함수 중 가장 큰 값을 그대로 이용한다.
3. 온-폴리시 vs 오프-폴리시
SARSA와 큐러닝의 학습 원리를 다시 살펴보자.
'SARSA는 현재 상태와 다음 상태에서 모두 ϵ-greedy 정책을 통해 행동을 선택한다.'
'큐러닝은 현재 상태에서는 ϵ-greedy 정책을 통해 행동을 선택하고, 다음 상태에서는 가장 큰 큐 함수를 이용한다.'
이때 SARSA는 온-폴리시 알고리즘이고, 큐러닝은 오프-폴리시 알고리즘이다.
오프 폴리시가 무슨 의미인지 먼저 살펴보자.
큐러닝처럼, 행동하는 정책과 학습할 때 사용하는 정책이 다른 경우를 오프 폴리시라고 한다.
온폴리시는 둘이 같은 경우를 의미한다.
각각 살펴보기 보다는, 온폴리시는 기존에 사용되던 방법이고, 오프 폴리시가 새로운 방법이라고 생각하면 이해하기 좋다.
따라서 오프 폴리시가 왜 필요한지 위주로 알아보자.
3. (1) SARSA의 문제점
SARSA에서 다음과 같은 상황이 발생했다고 해보자.

학습 초기에 랜덤하게 초기화 된 상황에서, 또는 학습 중이더라도 탐험에 의해 다음과 같은 이동이 발생했다.
at 에서 오른쪽으로 이동하고, at+1로 아래를 선택했더니 마이너스 점수가 발생했다.
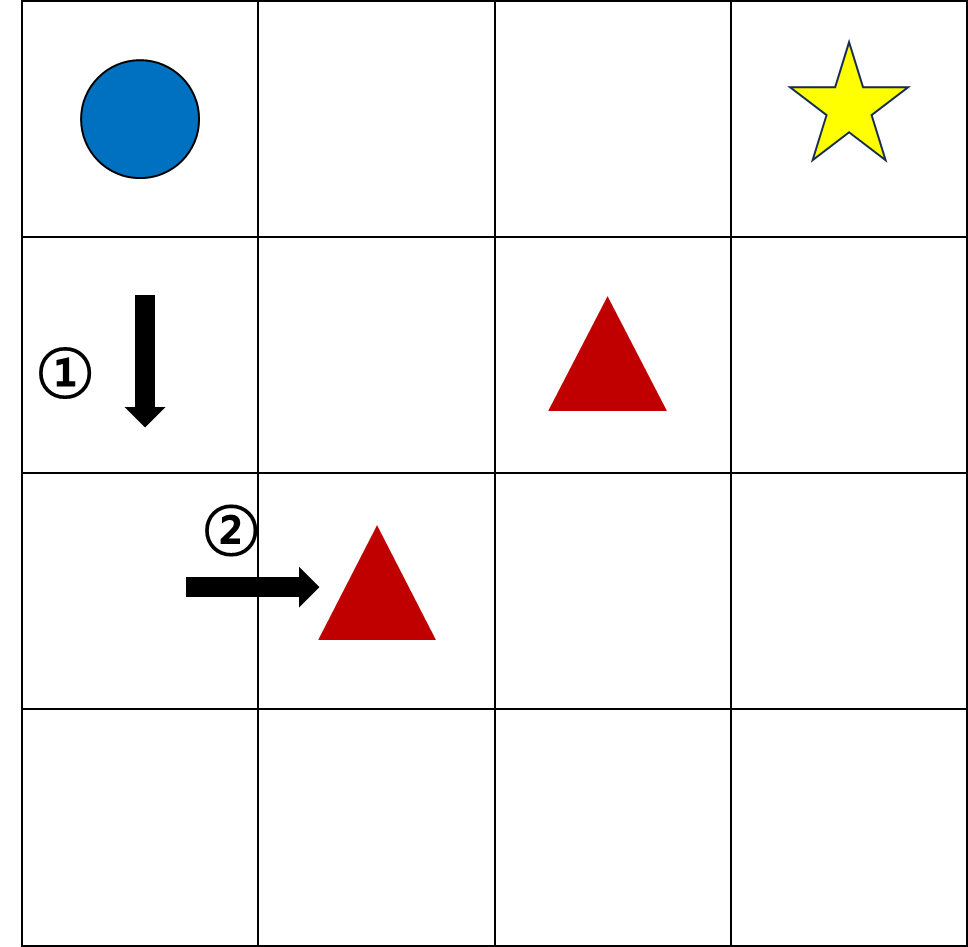
이 경우, s(0, 1)에서 오른쪽으로 이동하는 행동은 안 좋은 행동으로 평가된다.
아래의 경우도 대칭적이므로 마찬가지이다.
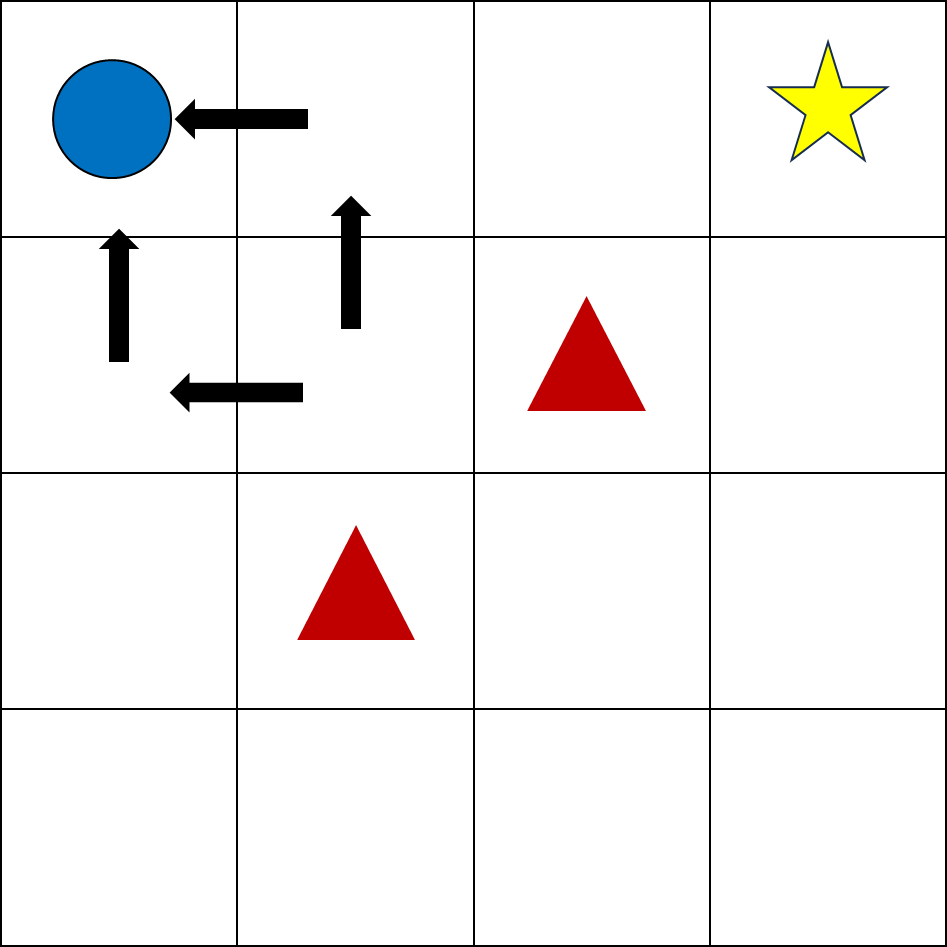
이렇게 되면 최악의 경우에는, 큐함수가 위와 같이 계산되어, 일종의 갇히는 현상이 발생한다.
물론 탐험에 의해 계속해서 학습하면 최적을 찾을 수 있겠지만, 어쨌든 학습이 길어지기 쉽다.
큐러닝에서는 이런 경우가 발생할까?
큐러닝에서는 다음 행동에서는 maxa′Q(st+1,a′) 을 통해 학습한다.
즉, 다음 행동은 제대로 행동하는 경우로 학습한다는 것이다.
SARSA에서는 (0, 1) 에서 '우측으로 이동'을 선택한 후, at+1을 고를 때 입실론 확률에 의해 잘못된 선택('아래로 이동')을 또 할 수 있다.
그러나, 큐러닝에서는 그렇지 않다.
따라서 위의 갇히는 예시는 발생하지 않는다.
3. (2) 직관적으로 차이 이해하기
바둑을 예시로 직관적으로 이해하는 것이 개인적으로는 더 도움이 되었다.
바둑에서 어떠한 한 수를 두고, 이 수를 평가하고 싶다.
이 수가 좋은 수인지 평가하려면, 앞으로 둘 때도 올바르게 둬야 평가가 가능하다.
극단적인 예로, 알파고가 어떤 한 수를 계산하고 두더라도, 그 뒤로 유치원생이 이어받아서 두면 그 수를 분석하는 의미가 없어진다.
SARSA에서는 어떤 수를 평가하려할 때, 가끔은 다음 수를 막 두기 때문에, 그 수를 잘못 평가하게 되는 경우가 있다.
반면 큐러닝에서는 적어도 평가하고 싶은 수 다음 수부터는 올바르게 둔다.
이것이 온폴리시와 오프폴리시의 개념적인 차이이다.
3. (3) 오프폴리시의 장점
큐러닝에서는 다음 선택은 제대로 행동하는 경우로 학습한다.
따라서 다음과 같은 장점이 있다.
(1) 지금의 행동을 보다 올바르게 평가할 수 있다.
(알파고와 유치원생 반례를 생각해보면 된다.)
이때 사실은 maxa′Q(st+1,a′) 도 계속해서 발전한다.
따라서 같은 행동을 다시 하더라도, 평가가 달라질 수 있다.
예를 들어, 예전에는 나쁘게 봤던 수가 있다. -> Q(s, a)
그런데 그 수 다음에 취할 수가 발전했더니 -> Q(st+1,a′),
알고 보니 두면 좋은 수였다.
와 같은 흐름이 가능한 것이다.
즉,
(2) 같은 행동에 대해서도 일종의 '재평가' 가 가능하다.
추가로 큐러닝 말고 오프폴리시 자체는 다음과도 같이 이용이 가능하다고 하다.
현재 행동을 선택할 때는 내 선택 이용하고, 이후의 행동에 대해서는 상대방의 행동을 학습하면,
(3) 턴 방식의 문제에서 상대방의 정책에 맞춰 정책을 설정하는 것이 가능하다.
※ 주의
'오프-폴리시가 더 우월한 알고리즘이구나'라고 생각이 들었지만, 꼭 그렇지는 않다고 합니다.
구글은 온폴리시를 선호한다고 하고, OpenAI는 오프폴리시를 선호한다는 얘기가 있네요.
정리
- SARSA는 시간차 예측 기반 on-policy 알고리즘이다.
- 큐러닝은 시간차 예측 기반 off-policy 알고리즘이다.
- Off-policy를 사용하면, 몇가지 장점이 있다.
'강화학습 > 강화학습 기초' 카테고리의 다른 글
| [강화학습 기초] 몬테카를로와 시간차 예측 (0) | 2023.08.13 |
|---|---|
| [강화학습 기초] 벨만 방정식과 다이나믹 프로그래밍 (1) | 2023.08.08 |
| [강화학습 기초] 가치 평가 함수와 벨만 방정식 (0) | 2023.08.07 |
| [강화학습 기초] 강화학습과 MDP (0) | 2023.08.05 |