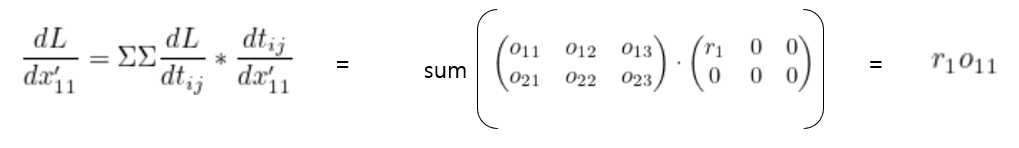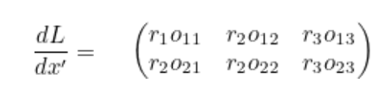※ 본 내용은 stanford에서 제공하는 cs231n 강의, 강의자료를 바탕으로 작성하였습니다.
Lecture 11에서는 detection과 segmentation에 대해 다루고 있다.

앞선 강의에서 classification에 대해 중점적으로 다뤘지만, 위에 소개된 detection이나 segmentation도 computer vision 분야의 핵심적인 tasks이다.
Sematic segmentation부터 instance segmentation까지 각가의 task와 관련 기술에 대해 살펴보겠다.
<Semantic Segmentation>
Semantic segmantation은 이미지 내의 모든 pixel에 대해 어떠한 class에 속하는지 labeling을 수행하는 task이다.

Instance segmentation이나 detection과의 가장 큰 차이 점은 각각의 객체를 구분하지 않는다는 것이다.
그 예시로 위 슬라이드에서 두 마리의 소를 구분짓고 있지 않다.
그렇다면 semantic segmentation은 어떻게 수행할 수 있을까?
- Sliding Window?
가장 먼저 window 크기만큼 이미지의 일부 영역에 classification을 수행하고, window를 이동시켜가며 이미지의 각 영역에 대해 classification을 수행하는 방법을 생각할 수 있다.
그러나 영역을 구분짓기 위해서는 window size가 크지 않을 것이고, 따라서 계산이 상당히 많이 필요하다는 것을 쉽게 예상할 수 있다.
- Fully Convolutional

Fully connected layer 등을 제외하고, 최종 출력까지 conv 연산의 결과가 되도록 모델을 설계하는 방법도 존재한다.
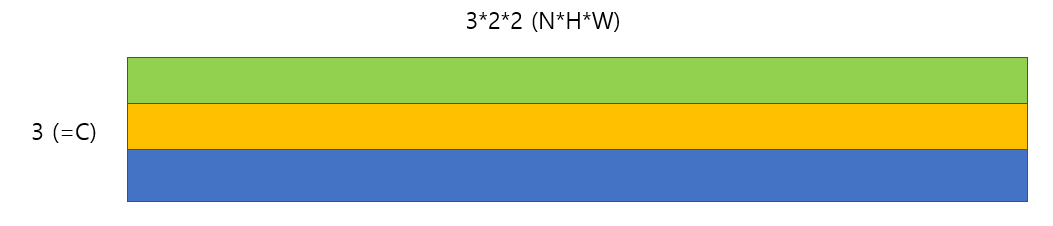
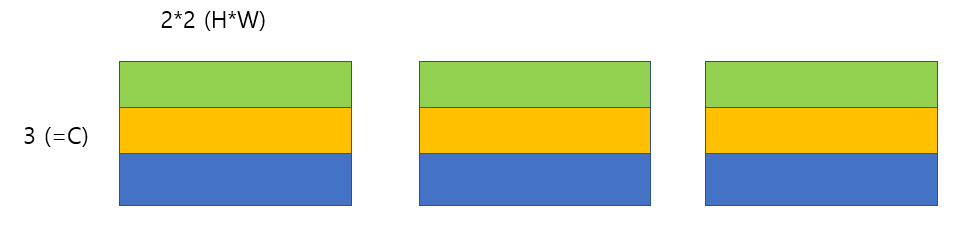
최종 출력은 CxHxW 크기가 될 것이고(C : # of category), 최종 output에서 각 pixel별로 score를 확인하여 classification을 수행하면 된다.
좋은 방법이지만 마찬가지로 high resolution image을 유지하기 위해서는 계산량이 상당히 많아지게 된다.
예를 들어 226x226 크기의 이미지가 주어지면 최종 출력도 226x226 크기가 돼야하므로 conv연산을 거치는 과정에서 연산이 상당히 많이 필요할 것이다.
이러한 문제는 downsampling과 upsampling을 어느 정도 극복할 수 있다.

Maxpooling 등의 방법으로 downsampling을 거쳐 데이터의 크기를 줄여서 처리한 후, 다시 upsampling을 겨쳐 원본 이미지의 크기에 맞춰 출력하는 방식이다.

Pooling과 반대되는 unpooling을 통해 upsampling을 수행할 수 있고, 위와 같은 방법들을 생각해볼 수 있다.
또한 umsampling 과정 또한 학습이 가능한 방법인 'Transpose Convolution'도 존재한다.

Transpose convolution은 input의 각 element를 filter에 곱해서(broadcasting) output을 출력하는 방법이다.
1차원 예시로 다시 한 번 나타내면 다음과 같다.

해당 과정이 'Transpose Convolution'이라고 불리는 이유는 다음과 같다.

기본적으로 모든 convolution 연산은 좌측과 같이 행렬곱으로 나타낼 수 있고, 해당 연산을 transpose하면 transpose convolution이 된다.
따라서 'Tranpose Convolution'이라는 이름을 사용하고,
그 외에 Deconvolution, Upconvolution 등의 명칭으로 불리기도 한다.
겹치는 영역에 대해서 평균을 취하지 않고 더하는 이유에 대해 질문이 있었는데, filter가 slide하며 겹치는 영역의 결과를 더하는 이유도 위 연산 과정을 따르기 때문이다.
실제로 scale이 달라지는 등의 문제가 존재하긴 하고, 다양한 방법으로 해결하려는 연구가 존재한다고 한다.
<Localization>

Localization은 classification뿐만 아니라 실제 그 객체가 위치한 영역을 탐지까지 하는 task를 의미한다.
단, detection과 달리 단 하나의 객체만을 탐지한다.
Localization은 classification과 유사하게 수행하고, 박스의 좌표에 대한 vector를 출력에 추가해서 regression처럼 다루는 방식으로 수행할 수 있다.
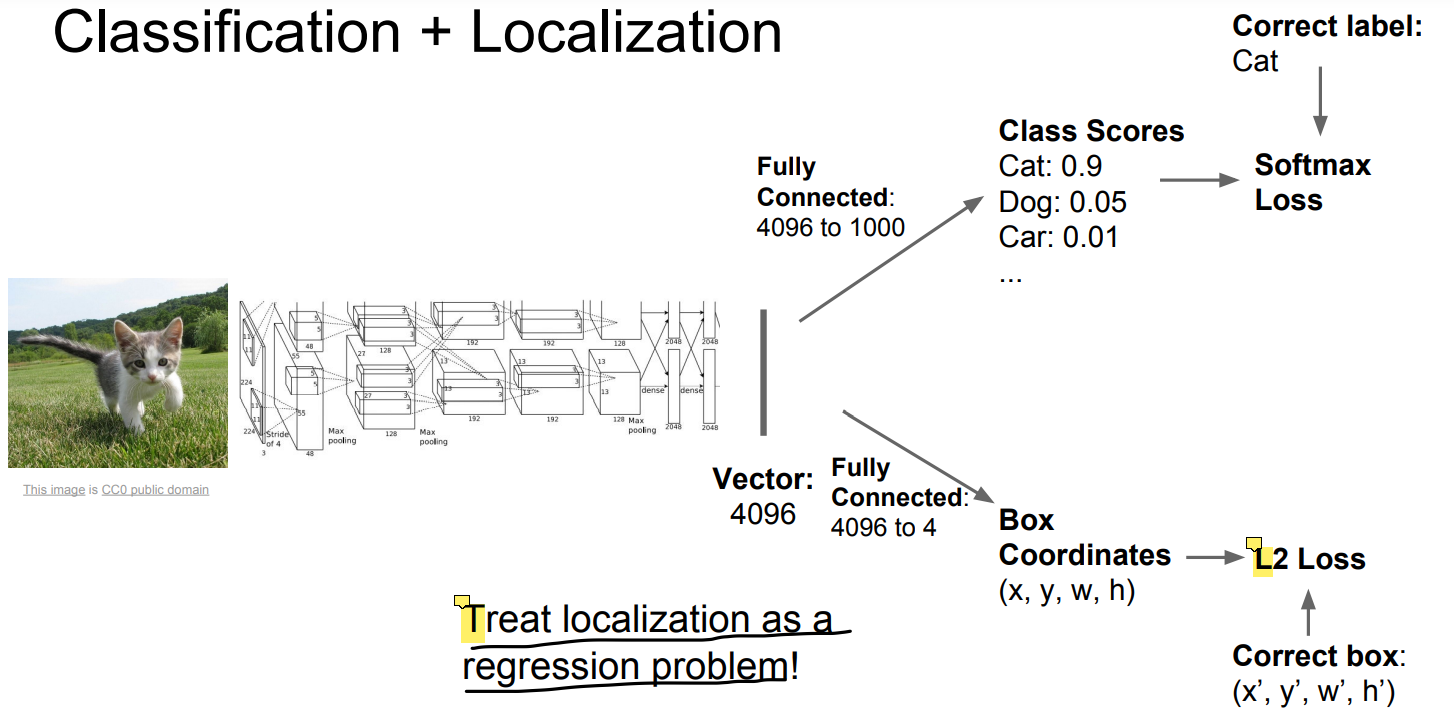
위와 같은 방법을 사용하면 (1) classification에 대한 loss, (2) regression에 대한 loss, 총 2가지의 loss가 존재하게 된다.
보통 이러한 경우 각 loss에 weight를 주어서 a*Loss1 + b*Loss2 등과 같이 하나의 loss로 통합해준다.
이때의 weight 또한 hyperparameters이지만, 설정에 따라 loss 자체가 달라지기 때문에 일반적인 hyperparameter와 달리 loss가 낮아지는 방향으로 선택하는 것이 어렵다.
따라서 loss외에 다른 지표를 하나두고, 해당 지표를 바탕으로 어떠한 weight 설정이 좋을 것인지 판단하는 방법을 사용하기도 한다.
※ Accuracy 등이 있을 것 같다.
또한 같은 convolution 구조를 이용하면서 fully connected layer만 fine tuning하는 방식으로 2개의 모델을 생성한 후,
각각 classification과 loss를 계산하도록 구현하는 방법에 대한 질문이 있었다.
가능한 방법이지만, 둘을 통합할 때 문제가 발생할 수 있으므로 가능한 하나의 모델로 수행하는 것이 좋다고 한다.
+ Pose Estimation
Regression을 접목하는 방식은 다양한 task로 확장이 가능하고, 대표적으로 아래와 같이 사람의 관절 위치를 탐지하는 것도 가능하다.
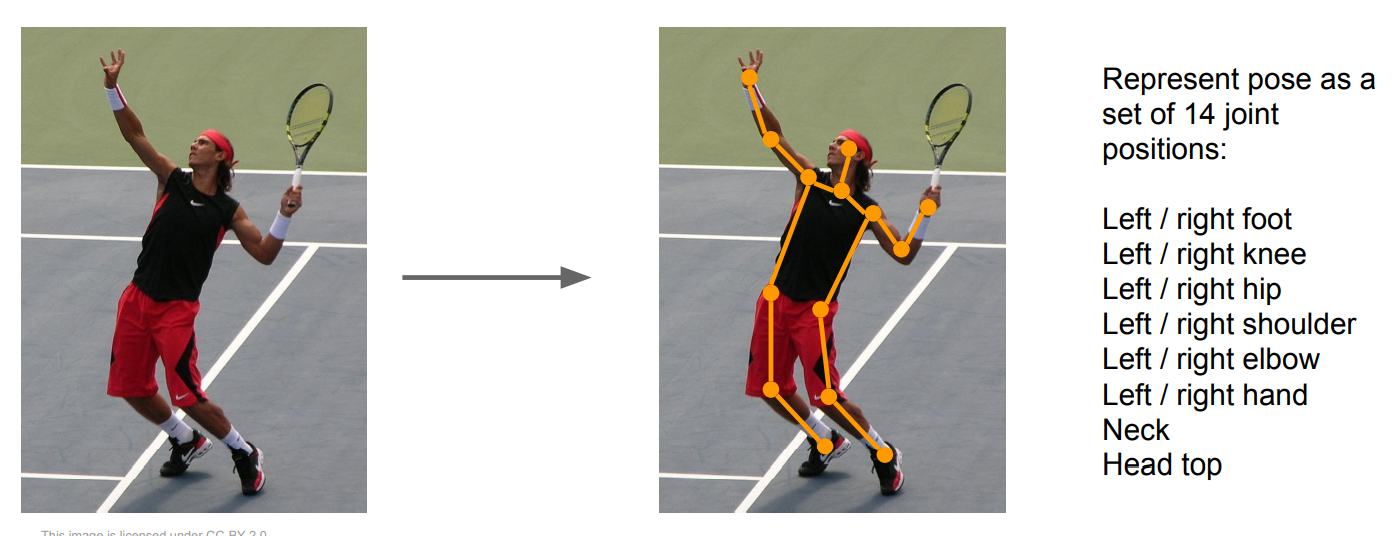
Localization에서 박스의 좌표를 다룬 것처럼, 각 관절 좌표에 대한 regression을 수행하도록 구현할 수 있다.
<Object Detectoin>
Object detection은 여러 개의 객체를 탐지하는 task이며, classification처럼 deep learning의 등장 이 후 크게 발전한 분야이다.
앞서 다룬 Localization과의 차이점은 여러 개의 객체를 탐지한다는 것이며, 따라서 객체의 수가 고정되어 있지 않으므로 Localization과 같이 구현할 수 없다.(Output의 수가 고정되어 있지 않으므로)
- Sliding Window?
가장 먼저 sliding window를 떠올려 볼 수 있지만, semantic segmentation에서와 마찬가지로 연산의 수가 매우 많아질 것이다.
- R-CNN, Region Proposals

R-CNN은 Region Proposal을 이용한다.
Region Proposals는 전통적인 image processing 알고리즘으로, 이미지 속에서 object를 포함할만한 영역을 표시해준다.
제안되는 영역이 많고 정확하지는 않아서 해당 방법만으로 detection은 불가능하고, 제안되는 영역에 대해서만 classification을 수행한다.
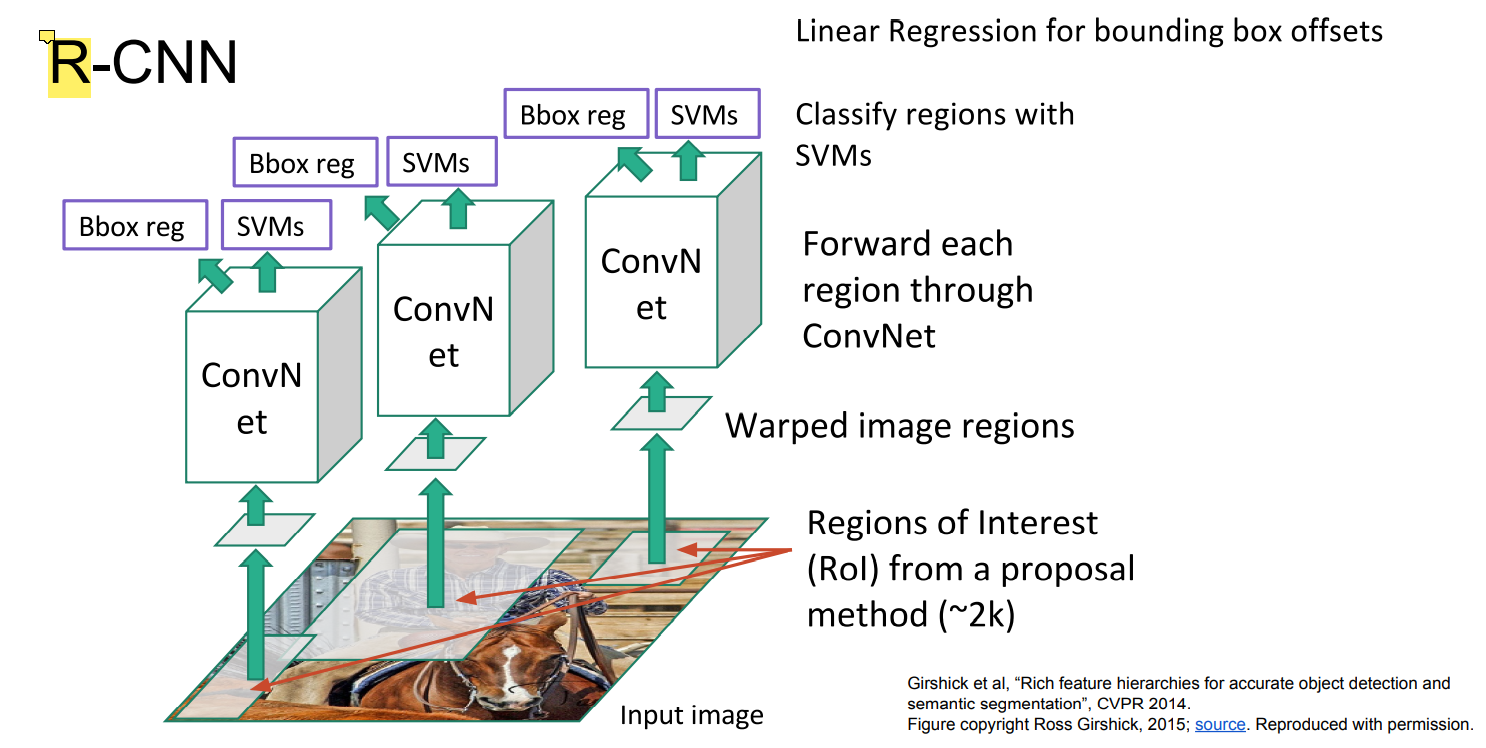
여기에서도
(1) classification에 대한 loss
(2) 제안된 영역의 적합성에 대한 loss
총 2가지 loss가 존재한다.
R-CNN은 그림에서 볼 수 있듯이 여러 번 연산을 수행하므로, 여전히 비효율적인 방법이다.
- Fast R-CNN
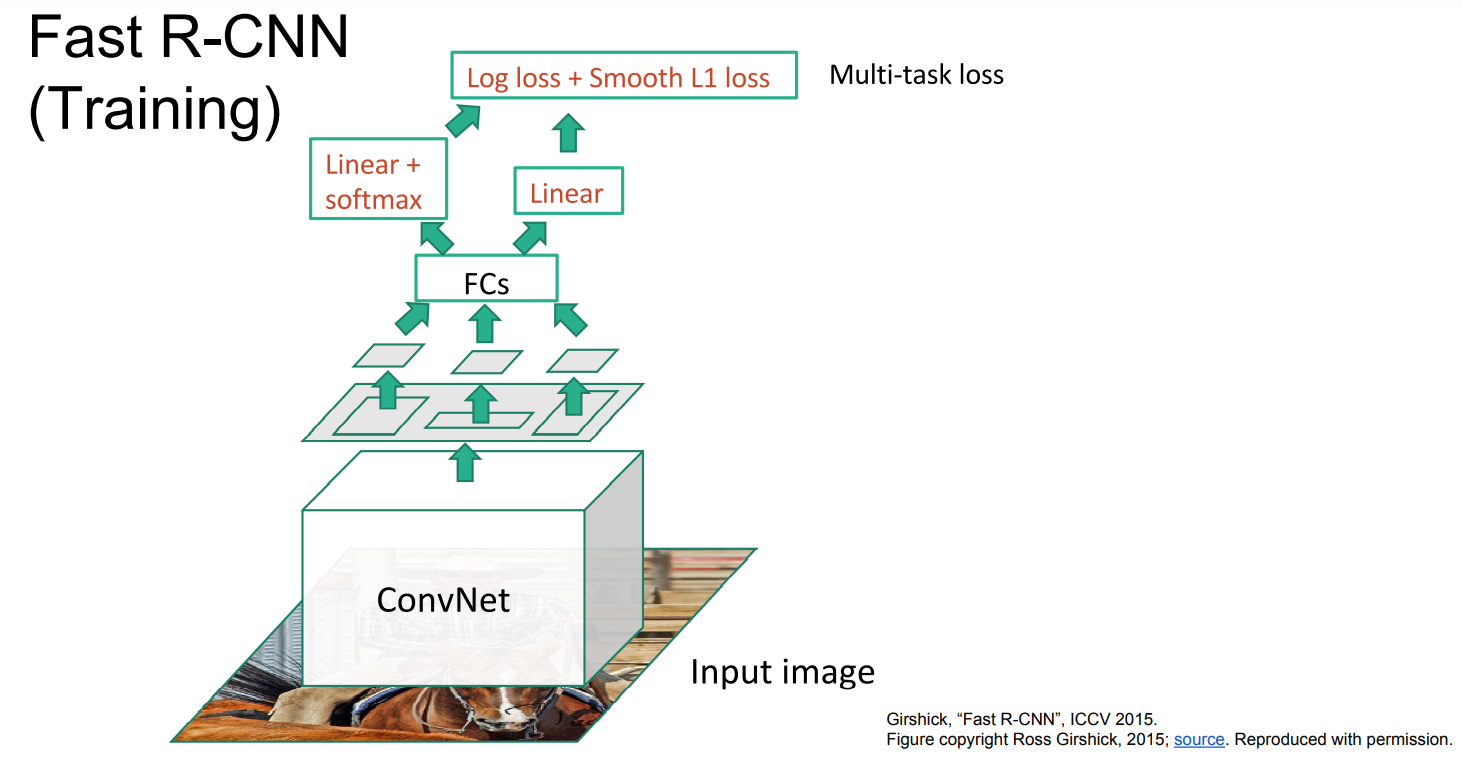
Fast R-CNN에서는 먼저 하나의 Convoultion network를 거친 결과에 대해서 region proposal 결과를 이용하는 방법이다.
그림에서는 작아지는 것으로 표현되었지만, ConvNet을 거친 후의 size(HxW)는 input image와 동일하고, input image로 생성된 region proposal 영역을 ConvNet을 거친 결과에 적용하는 것이다.
이 후에는 각 영역에 대해 FC layers를 이용해 classification을 수행한다.
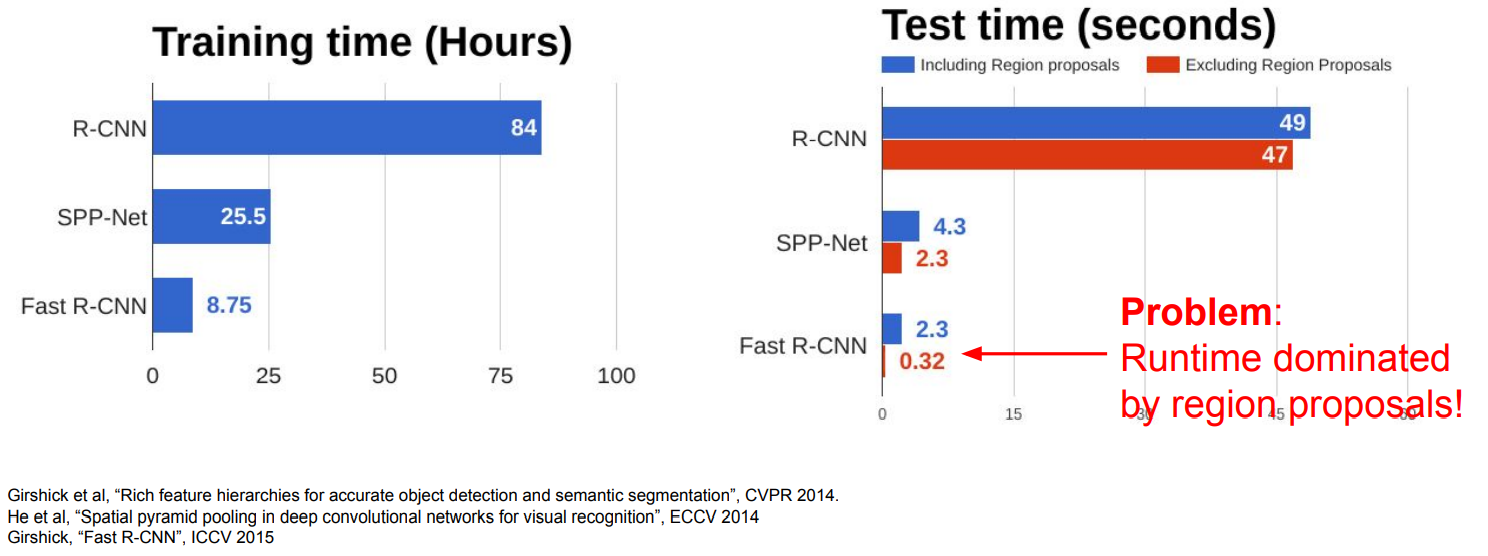
Fast R-CNN은 R-CNN에 비해 훨씬 빠르지만, runtime이 region proposals 알고리즘의 계산 시간에 의해 결정된다는 단점이 존재한다.
(SPP는 R-CNN과 Fast R-CNN의 중간 정도의 방법이라고 한다.)
따라서 최종적으로 Faster R-CNN을 통해 그러한 문제도 극복한다.
- Faster R-CNN
Faster R-CNN에서는 region proposal도 deep learning으로 처리한다.
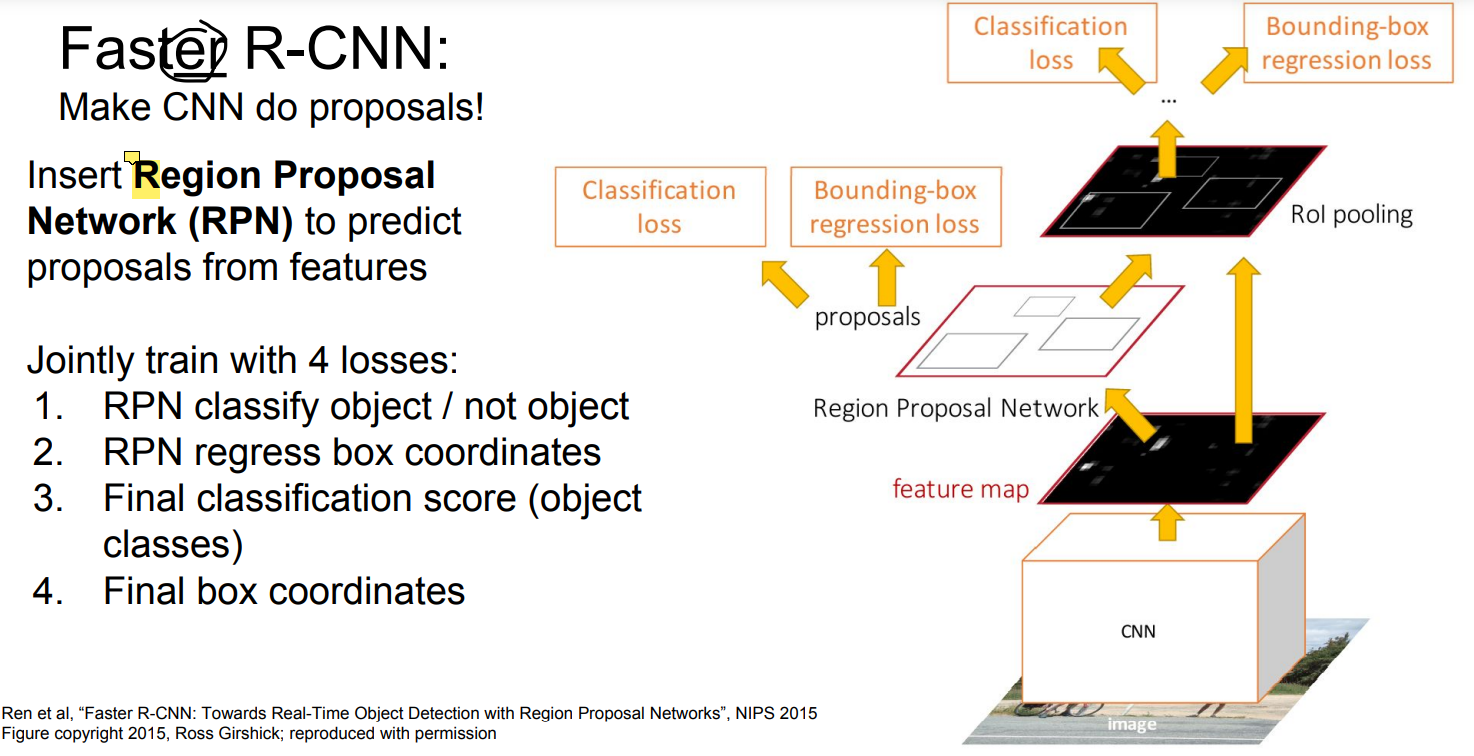
RPN(Region Proposal Network)를 추가하여 region proposal이 오래 걸리던 문제를 해결하는 것을 제외하고는 Fast R-CNN과 동일하다.
Regision proposal에 대한 loss가 2개 추가되어 총 4가지 loss가 존재하게 된다.
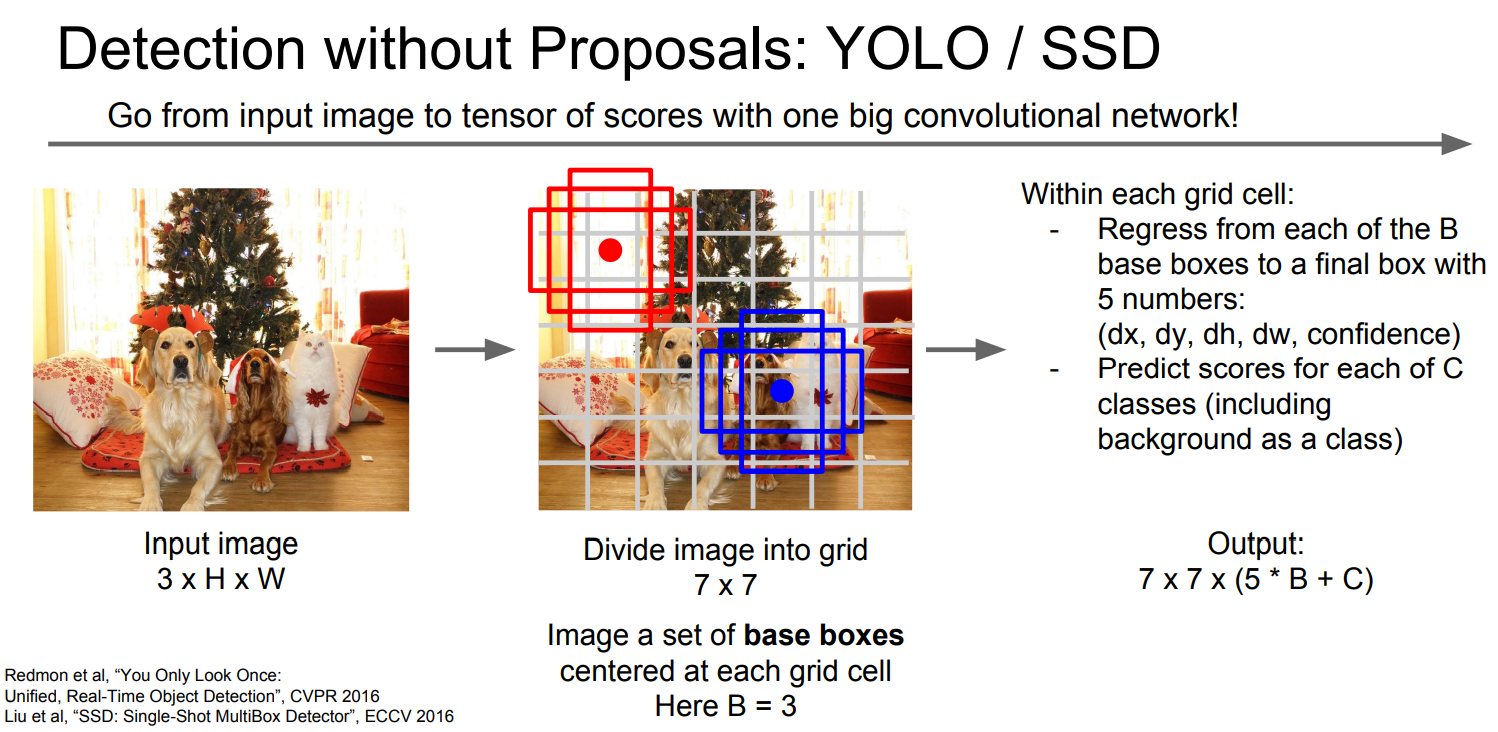
그 외에 YOLO나 SSD같은 방법도 존재한다고 한다.
이미지를 grid단위로 나누고 -> grid 마다 모든 base box 경우에 대해 <dx, dx, dh, dw, confident>를 예측
-> classification을 수행
위와 같은 순서로 동작한다고 한다.
<Segmentation>

Multiple objects를 탐지하고, pixel 단위로 segmentation을 수행하는 task이다.
앞서 다룬 semantic segmentation과 detection을 결합하여 구현할 수 있다.

Object detection을 먼저 수행하고, 제안되는 bounding boxes마다 sematic segmention을 수행하는 방법이라고 생각할 수 있다.
'Computer Vision > cs231n' 카테고리의 다른 글
| [Lec 13] Generative Models (0) | 2022.01.26 |
|---|---|
| [Lec 12] Visualizing and Understanding (0) | 2022.01.24 |
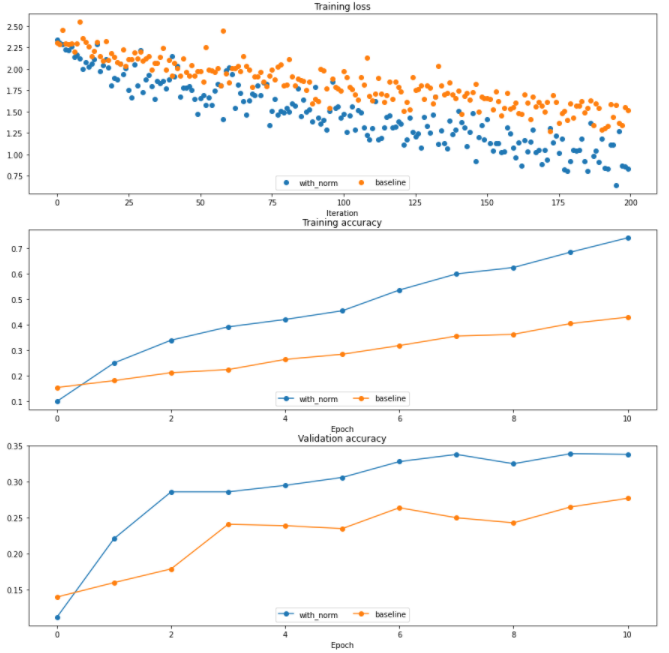
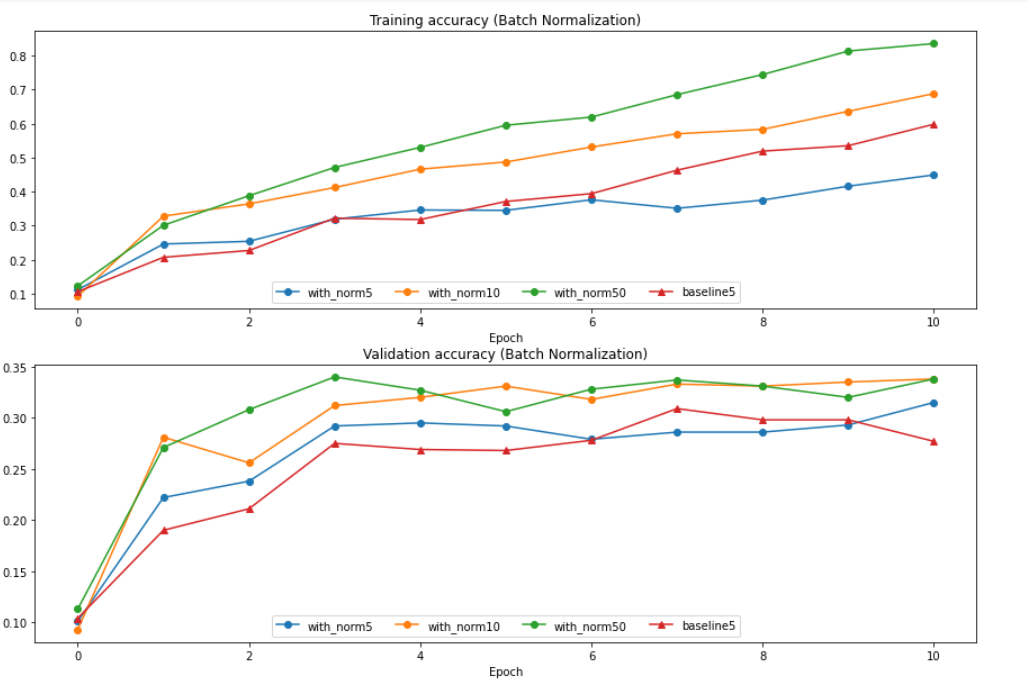
| [Assignment 2] Convolution 역전파, Spatial Batch Normalization (1) | 2022.01.21 |
| [Assignment 2] Batch Normalization, 역전파 (0) | 2022.01.20 |
| [Lec 10] Recurrent Neural Networks, RNN (0) | 2022.01.19 |