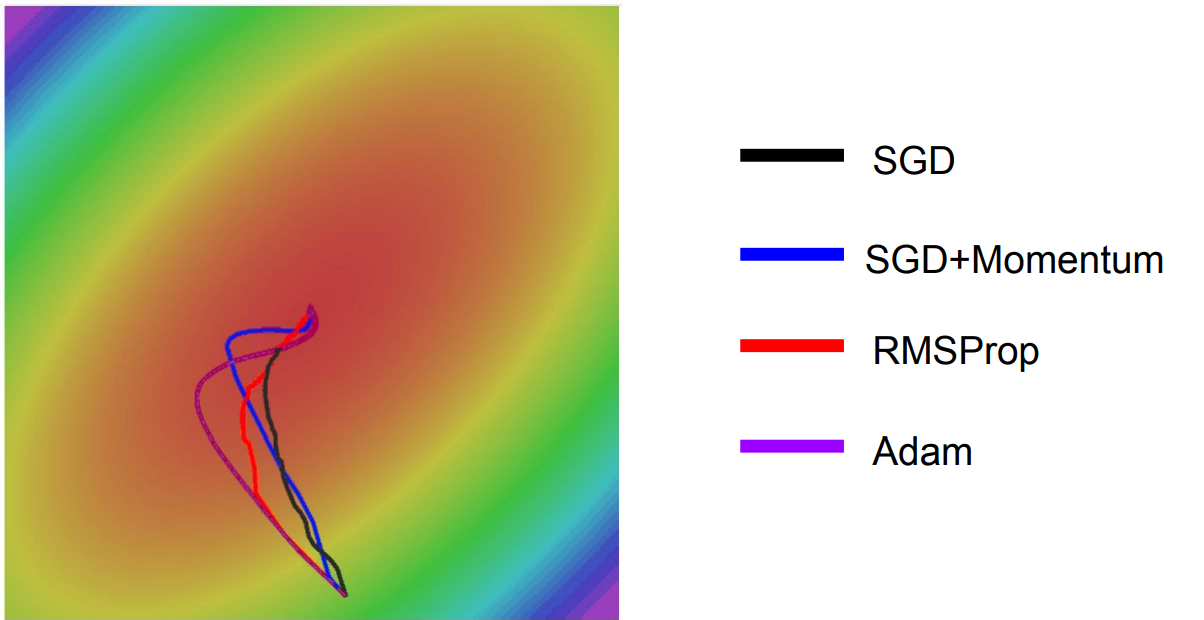
※ 본 내용은 stanford에서 제공하는 cs231n 강의, 강의자료를 바탕으로 작성하였습니다.
Lecture 10에서는 기본적인 RNN 구조와 비전 영역에서의 RRN 활용 그리고 LSTM 등에 대해 다루고 있다.
<Recurrent Neural Networks, RNN>
RNN은 sequences를 다루기 위해 개발된 구조이다.
기존의 모델은 하나의 input에 대해 하나의 출력을 갖는 one to one 구조였지만,
RNN은 다음과 같은 구조를 갖는다.

수행하려는 tasks에 따라 다양한 수의 input과 output을 갖을 수 있다.
- one to many
ex) 하나의 input 이미지에 대해 설명 하는 문장(여러 단어) 출력, image captioning
- many to one
ex) 문장(여러 단어)을 보고 긍정, 부정 등 분석을 출력, sentiment classification
- many to many
ex) 문장에서 문장을 생성, 기계 번역
- many to many
ex) 동영상에서 여러 개의 frame마다 분석 수행, video classification on frame level
- non-sequence data
Sequence data가 아닌 경우에도 RNN을 사용할 수 있다.
예를 들어, 픽셀을 순차적으로 처리하며 이미지를 생성하는 것도 가능하다.
(강의에서는 mnist dataset을 생성하는 예시 동영상을 제공한다.)
- Architecture

RNN에는 input vector 뿐만 아니라, hidden state(vector)라는 것이 추가되어,
input과 hidden state를 input으로 출력을 계산한다.
수식을 조금 더 자세히 살펴보면 다음과 같다.
$ h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t)$
$ y_t = W_{hy}h_t $
(3가지 weight matrix가 서로 다름에 주의)
계산한 state가 다음 출력을 위한 input으로 입력되는 형태이다.
재귀적으로 표현된 그래프를 풀어서 계산 그래프의 형태로 나타내면 다음과 같다.

계산된 hidden vector를 바탕으로 y를 출력할 수도 있고 그렇지 않을 수도 있다. 이는 task에 따라 달라진다.
Many to many task라면 각 hidden state마다 output을 출력할 것이고, many to one task라면 맨 마지막의 hidden state만을 이용해 출력을 만들어낼 것이다.
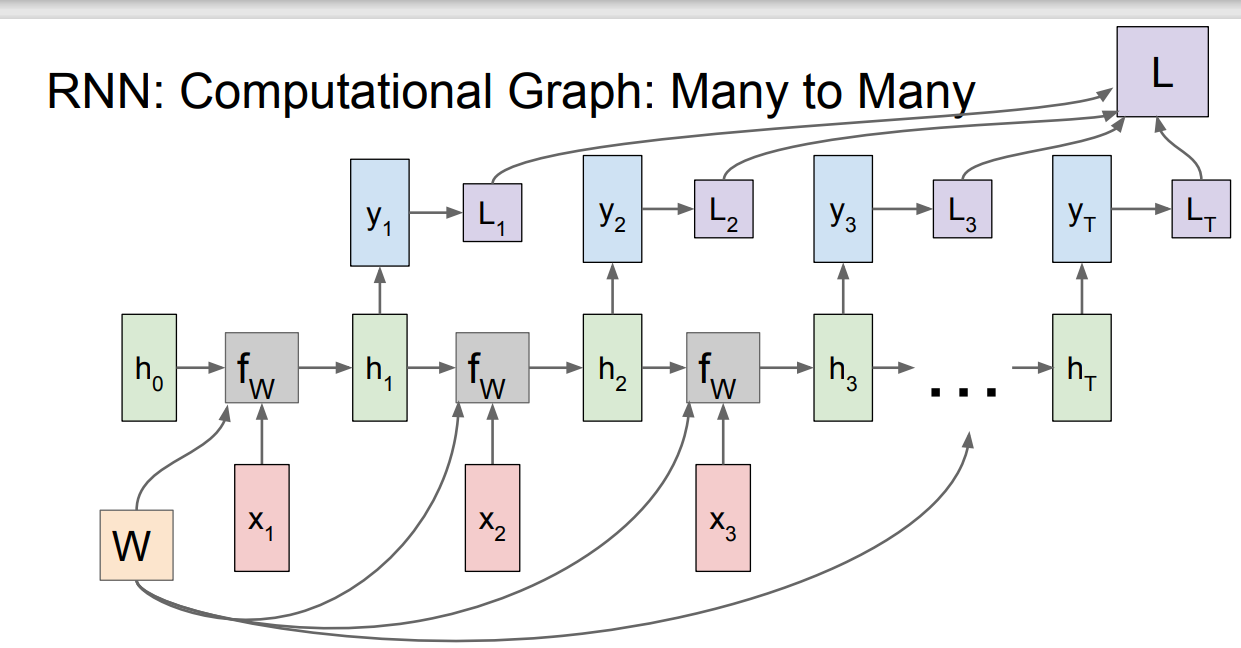
Many to many task의 경우 loss는 위와 같이 계산될 것이다.
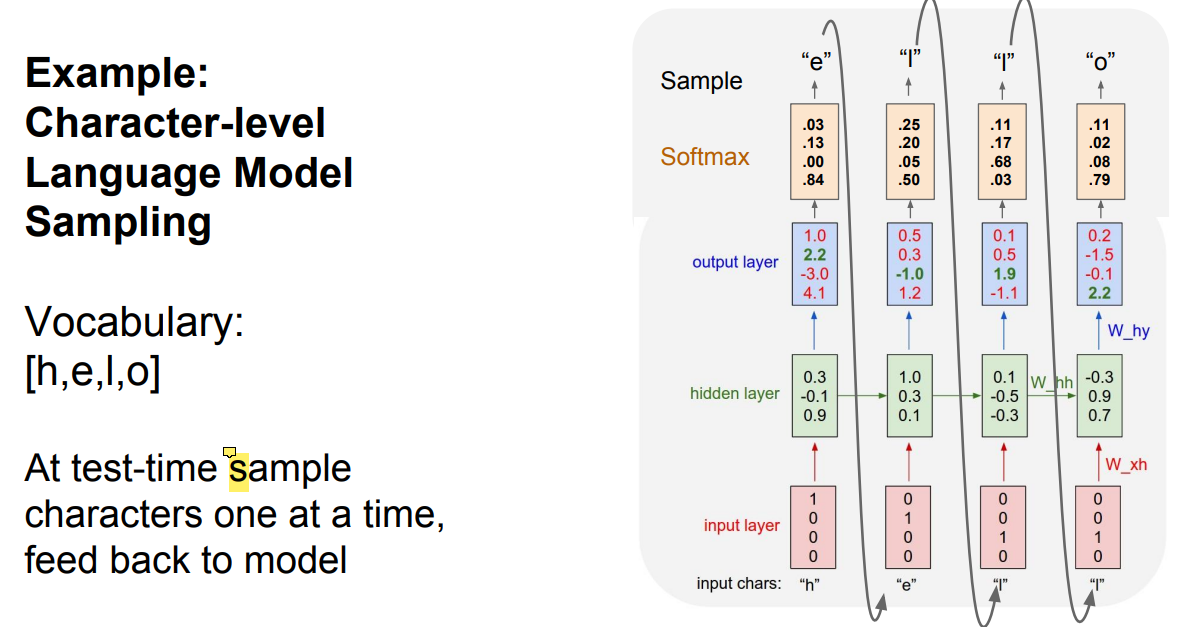
RNN을 이용하여 prefix가 주어졌을 때 다음으로 어떠한 문자가 출력되어야 하는지 예측하는 예시이다.
문자를 {h, e, l, o}로 한정시키고, 각각의 문자는 one-hot encoding을 통해 vector로 대응시켰다.
$ h_t = tanh(W_{hh}h_{t-1} + W_{xh}x_t)$
$ y_t = W_{hy}h_t $
앞서 살펴본 위 식을 바탕으로 계산하면 hidden layer와 ouptut layer가 계산된다.
현재 그림에서 앞의 input에 대해서는 잘못된 예측을 수행하고 있긴 하지만, 마지막의 'l'에 대해서는 제대로 'o'를 예측하고 있다.
$ W_{hy}, W_{hh}, W_{xh}$가 적절하게 학습되면 앞의 layers도 정확해질 것이다.
RNN in test time
RNN에서는 종종 어떠한 class에 대한 확률이 가장 높게 출력되더라도 test time에는 가장 높은 확률을 가진 값을 출력하는 것이 아니라, 'sample'하는 방식(확률을 출력될 확률로 해석)으로 출력을 선택한다.
이렇게 함으로써 좀 더 다양한 출력을 생성할 수 있다.
Truncated Backpropagation

RNN에서는 sequences를 다루다보니 sequences가 매우 길어지는 경우 역전파를 계산하는 것에 엄청난 연산이 필요하다.
따라서 일정 길이마다 구분하여 loss를 계산하는 기법이 truncated backpropagtion이다.
Applications
RNN을 다양한 데이터에 train시킨 결과를 보여주고 있다.(prefix로 다음 단어를 출력하는 RNN 모델)
셰익스피어의 책을 학습시키면 유사하게 글을 생성하고, C 코드를 학습시키면 그럴듯한 C 코드를 생성한다.

학습 데이터로 부터 이러한 문자 이후에는 이러한 문자가 나올 것이다라고 학습한 것이기 때문에,
모양은 그럴듯 하지만 정상적인 code는 아니다.
Interpretation
CNN에서 각 filter가 직선이나 edge같은 feature를 학습하는 것처럼, RNN에서의 hidden vectors도 해석 가능한 feature를 학습한다고 한다(항상 해석 가능한 것은 아니다.).
Vector에서 특정 element마다 특정 역할을 수행하는 방식이다.
예를 들어, 2번째 element가 큰 값을 출력할 수록 현재 큰 따옴표안에서 글을 쓰고 있음을 의미하는 것이고,
4번째 element가 작은 값을 출력할 수록 문장을 끝내야할 시점이 다가온다는 것을 의미하는 등의 방식이다.

실제 training 결과 어떠한 element가 큰 따옴표를 detect하는 결과이다.
해당 element의 출력이 클수록 파란색에 가깝게 나타냈다.
Image Captioning
이미지에 대해 설명하는 문장을 출력하는 task를 image captioning이라고 한다.

먼저 image는 CNN의 input으로 입력되고, CNN의 출력 결과가 RNN에 주어지는 형태로 image captioning을 수행할 수 있다.
Image Captioning with Attention

Image captioing을 수행할 때 attention을 이용할 수도 있다고 한다.
강의에서도 개념적인 응용에 대해서 설명하고 있어 자세한 동작은 알 수 없지만,
기존 image captioning에서는 CNN의 결과가 RNN으로 전달된 후 RNN의 각 layer마다 단어를 출력하지만,
attention을 이용하는 방식에서는 단어와 attention을 모두 출력하여 attention을 이미지에 적용한 후 다시 input으로 사용하는 구조인 것으로 보인다.
<Multilayer RNN>

RNN을 잘 알지는 못했지만, 기존에도 대략적인 설명을 보게되면 항상 layer가 하나인 것에 의문이 있었는데,
실제로 layer의 depth가 2개 이상인 multilyaer RNN도 존재한다고 한다.
자세한 동작에 대해서는 다루지 않고 소개하는 정도로만 다루고 있다.
<LSTM, Long Short Term Memory>
RNN의 문제
LSTM에 대해 살펴보기에 앞서 먼저 일반적인 RNN의 문제를 살펴보자.

역전파가 전개되는 과정을 나타낸 그림으로, 빨간색으로 나타난 길로 흐르는 역전파를 생각해보면 계속해서 $ W^T$가 곱해지게 된다.
W가 scalar라고 생각해보면 W가 1보다 큰값이라면 sequence가 길어질수록 gradient값은 폭발할 것이고,
W가 1보다 작은 값이라면 gradient값은 0에 수렴할 것이다.
편의를 위해 scalar인 경우를 생각해봤지만 W가 matrix인 경우에도 동일한 문제는 발생한다.
W가 1보다 커서 exploding gradients가 발생하는 경우에는 gradient clipping이라는 기법을 통해 해결하기도 한다.
매번 값이 정해둔 threshold보다 커질때마다 scale을 해주는 방식이다.
그러나 gradient vanishing 문제는 구조적 문제를 해결하지 않고서는 해결하기 어려웠다.
Gradient vaninshing 문제를 해결하기 위해 새롭게 등장한 구조가 LSTM이다.
Architecture

그림이 조금 복잡해보인다. 기본적으로 RNN과 동일한 구조를 갖지만,
hidden state에 이어 Cell state, $ C_t$까지 추가되었다고 생각하면 된다.
$ c_t$와 $ h_t$의 계산은 다음과 같고,

두 state에 계산되는 $ i, f, o, g$의 계산은 다음과 같다.

수식이 복잡해 보이는데,
(1) W와 $ h_{t-1}$과 $ x_t$를 이어붙인 vector를 곱해주고,
(2) $i, f, o$에 대해서는 sigmoid, $ g$에 대해서는 tanh를 적용해서 계산해준다는 의미이다.
여기에서 사용되는 $ i, f, o, g$의 의미는 다음과 같다.
- $ i$
Cell에 추가할지 말지를 결정
- $ f$
전달된 cell을 얼마나 forget할지
- $ o$
Cell의 정보를 얼마나 노출할지(hidden state로 전달할지)
- $ g$
Cell에 얼마나 더 입력할 지
(유일하게 tanh를 적용한 결과로, -1 ~ 1까지의 값을 같는다.)
위 의미를 바탕으로 수식을 다시 한 번 살펴보면 LSTM에서 어떠한 계산을 하는 것인지 조금 더 이해할 수 있다.
Cell state는 이전의 cell state보다 $ f$만큼 약해지고, $ i$와 $g$이 element-wise 곱이 보충되며,
hidden state는 cell state를 얼마나 들어낼지 $ o$에 의해 결정된다.
사실 위 내용만으로 LSTM이 어떻게 동작하는지 해석하기에는 어려움이 있지만,
앞서 얘기했듯이 gradient vanishing 문제를 해결할 수 있다는 구조적인 장점을 집중적으로 살펴보자.


Cell state로 흐르는 gradient의 이동은 빨간색 화살표를 따른다.
역전파 과정을 살펴보면, tanh를 거치는 과정은 RNN과 동일하고, '+'는 역전파를 방해하지 않는다.
RNN과 차이가 발생하는 부분은 W대신 $ f^T$를 곱해주게 된다는 점이다.
f는 각 단계마다 input(x와 이전 단계의 hidden state)과 W의 곱으로 생성되는 고정되지 않은 값이다.
따라서 RNN과 달리 계속 같은 수($ W^T$)를 곱해주는 것과 달리, 매번 다른 값을 곱해주기 때문에 gradient vanishing 문제가 발생하지 않는다.
결국 중요한 것은 Weight에 대한 미분인데, W에 대한 미분의 계산에도 cell state로 전달된 역전파 값이 사용되므로, cell state로 전달되는 역전파가 잘 전달되면 W의 미분도 잘 이뤄진다.
이러한 점에서 ResNet과 유사하다고도 볼 수 있으며, 둘의 중간 단게로 highway networks 라는 것도 존재한다고 한다.
'Computer Vision > cs231n' 카테고리의 다른 글
| [Assignment 2] Convolution 역전파, Spatial Batch Normalization (1) | 2022.01.21 |
|---|---|
| [Assignment 2] Batch Normalization, 역전파 (0) | 2022.01.20 |
| [Lec 9 ]CNN Architectures (0) | 2022.01.17 |
| [Lec 8] Deep Learning Software (0) | 2022.01.16 |
| [Lec 7] Training Neural Networks, Part2 (0) | 2022.01.15 |