※ 본 글은 '[도서]파이썬과 케라스로 배우는 강화학습' 및 '[유튜브]혁펜하임의 트이는 강화학습'을 학습하고 작성한 글입니다.
1. 강화학습이란?
1. (1) 딥러닝과의 차이
강화학습에 대해 본격적으로 공부하기에 앞서, 강화학습이 어떤 것인지 살펴보자.
먼저 강화학습은 인공지능의 일부이다. 그러나 요즘 가장 일반적인 AI인 지도학습과는 다르다.
강화학습에 딥러닝 모델을 함께 사용하는 경우가 많긴 하지만(심층강화학습), 딥러닝 모델을 사용한다는 것이 지도학습을 사용한다는 의미는 아니다.
지도학습, 비지도학습, 강화학습
지도학습은 데이터와 정답(라벨)을 통해 모델을 학습시킨다.
비지도학습은 주어진 데이터 속에서 정답이 없이 학습한다.
강화학습은 주어진 데이터가 아니라, 주어진 환경 속에서 '보상'의 개념을 통해 에이전트가 스스로 학습한다.
(여기서 에이전트란, 딥러닝에서 모델을 의미한다고 생각하면 된다.)
1. (2) 그렇다면 왜 강화학습을 사용하는가
지도학습, 비지도학습, 강화학습이 각각 어떻게 동작하는지 간단하게 정리해봤다.
차이는 알겠는데, 최근엔 지도학습이 주류이다.
그렇다면 왜 강화학습을 이용할까?
강화학습을 통해 해결하고자하는 문제 자체가 다르기 때문이다.
강화학습에서 해결하고자 하는 문제는, 순차적으로 어떻게 행동할지 결정하는 것이다.
좀 더 구체적으로는 MDP(Markov Decision Process)로 정의되는 문제를 해결하는 방법 중 하나가 강화학습이다.
※ 순차적인 결정 자체는 RNN으로도 가능하지만, 강화학습은 MDP로 정의되는 문제를 해결한다는 점에서 차이가 납니다.
또한 엄밀히 MDP로 정의할 수 없는 문제더라도, 강화학습을 적용할 수 있고, 실제로는 RNN과 강화학습을 함께 사용하는 경우도 일반적이라고 합니다. 글 후반에 나오는 Markov 가정까지 살펴보면 이해될 것입니다.
여기서 MDP가 무엇인지 살펴보자.
2. MDP(Markov Decision Process)
2. (1) MDP란무엇인가
앞서 강화학습은 MDP로 정의되는 문제를 해결하는 방법이라고 했다.
여기서 MDP란, 순차적 행동 결정 문제를 수학적으로 정의한 것이다.
MDP로 정의되기 위해서는 Markov 속성이 성립해야 한다.
Markov 가정에 대해 살펴보기 위해, MDP로 정의되는 문제의 구성요소를 먼저 살펴보자.
2. (2) MDP 구성요소
상태, 행동, 보상, 상태 변환 확률, 할인률
위 5가지가 MDP의 구성요소이다.
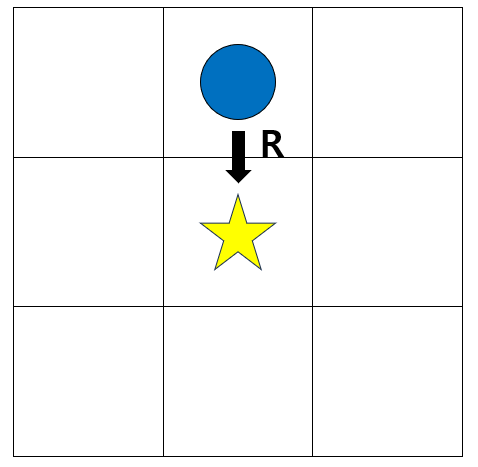
강화학습 기초 설명에 빠지지 않는 '그리드 월드'를 통해 각각에 대해 살펴보자.
그리드 월드
위는 그림을 파란색 원을 이동하여, 별 위치에 도달하면 보상을 받는 그리드 월드이다.
① 상태 S - 환경 속 가능한 상태의 집합
말 그래도 주어진 환경 속 가능한 상태의 집합이다.
상태는 개발자가 직접 정의해야 한다. 핵심은 정의한 상태가 에이전트가 학습하기에 충분해야 한다.
위 그리드 월드에서는 보통 원의 현재 위치를 상태로 정의한다. 이를 다음과 같이 표현한다.
S = {(0, 0), (0, 1), (0, 2), (1, 0), ..., (2, 2)}
② 행동 A - 상태 S에서 선택 가능한 행동의 집합
어떠한 상태에 있을 때, 에이전트가 취할 수 있는 행동의 집합이다.
예를 들어, 위 그리드 월드에서는, 상하좌우로만 움직일 수 있다. 이를 다음과 같이 표현한다.
A = {상, 하, 좌, 우}
③ 보상 - 상태 s 에서 행동 a를 했을 때 주어지는 보상
시점 t에서 s 상태이고, a 행동을 취했을 때, 전달되는 보상을 $ R_t $ 라고 표현한다.
(경우에 따라 $ R_{t+1} $ 로 표현하기도 합니다.)
보상은 함수로 다음과 같이 표현하게 된다.
$ r(s, a) = E[R_{t} | s_t, a_t] $
여기서 기댓값의 개념이 적용된 이유는, 같은 행동을 하더라도 '환경'에 따라 그때그때 보상이 달라질 수 있기 때문이다.
④ 상태 변환 확률
상태 변환 확률은 용어만으는 와닿지 않는다.
상태 변환 확률이란, s에서 a라는 행동을 했을 때 s'에 도달할 수 있는 확률을 의미한다.
이는 환경에 의해 결정된다.
여전히 와닿지 않는데, 예를 드는 편이 낫다.
위 그리드 월드에 이상한 조건이 있다고 생각해보자. (0, 0)에서 오른쪽으로 이동하는 행동을 선택하더라도, 매번 (0, 1)로 가는 것이 아니라, 10번 중에 1번은 (1, 0)으로 이동된다. 이처럼 행동이 같더라도 매번 같은 상태으로 변경된다는 것이 보장되지 않을 수 있으므로, 상태 변환 확률이 정의되어야 한다.
수식으로는 다음과 같이 표현한다.
$ P^{a}_{ss'} = P[s'|s_t, a_t] $
⑤ 할인률
할인률 역시 용어만으로는 와닿지 않는다. 예를 들어보자.
위 그리드 월드에서 보상을 R이라고 하고, 위치를 (1, 1)로 옮겨보자.
어느 시점 t에서 s = (0, 1) 이라면, 아래로 이동할 때 얻을 수 있는 보상은 R일 것이다. 즉, r((0,1) , '하') = R.
이는 명확하다.
그렇다면 다음은 어떨까?
이렇게 돌아 가서 얻은 보상 역시 R 이라고 표현해도 될까?
느낌적으로만 생각해도, 이렇게 생각하면, 에이전트가 올바른 판단을 찾지 못할 것이 명확하다.
미래에 얻는 보상일 수록 일종의 패널티를 적용해야 한다.
이를 위해 할인률 $ \gamma (0 \leq \gamma \leq1) $ 를 한 단계마다 곱하게 된다.
따라서 위 경우, 얻은 보상은 $ \gamma^2R $로 판단해야 한다.
2. (3) Markov 가정
다시 돌아와서, 앞서 DMP로 정의하려면 Markov 속성을 만족해야 한다고 했던 내용을 살펴보자.
한마디로, 현재 상태가 중요하지, 현재 상태에 어떻게 도달했는지 중요하지 않아야 한다는 것이다.
이 상황을 다시 살펴보자. 사실 (0, 1)에 도달하기 까지는 어떤 과정이 있었는지 모른다.
(0, 0) 에서 우측으로 이동했을 수도 있고, 아니면 반시계 방향으로 한바퀴를 돌고 (0, 1)에 도달한 것일 수도 있다.
그러나 이 과정이 현재의 의사결정에 영향을 미치지 않는다. 어떻게 왔든, 아래로 이동하는 행동을 선택해야 하는 것은 명확하다.
※ 본 내용은 stanford에서 제공하는 cs231n 강의, 강의자료를 바탕으로 작성하였습니다.
Lecture 16에서는 lecture 13에서 간단하게 다뤘던 adversarial examples에 대해 다루고 있다.
Noise로 보이는 필터를 중심으로 왼쪽과 오른쪽의 판다 이미지는 사람이 보기엔 둘 다 판다 이미지이고, filter를 더한 것조차 알아보기 어렵다.
그러나 머신러닝 모델은 좌측의 이미지를 60% 확률로 판다로 예측하고, filter가 더해진 오른쪽의 판다 이미지는 99% 확률로 긴팔 원숭이로 예측한다.
이러한 이미지들을 Adversarial Examples라고 하고, 이러한 이미지들은 model을 속일 수 있다.
그리고 이러한 adversarial examples는 매우 쉽게 생성할 수 있다.
먼저 이러한 문제는 왜 발생할까?
- From overfitting or from underfitting?
처음엔 연구자들은 이러한 현상이 overfitting에 의한 것이라고 생각했다.
Model의 classification boundary가 너무 복잡하고 정교하다 보니 잘못된 boundary가 존재하고, 해당 영역으로 인해 misclassification이 발생한다고 보았다.
그러나 이는 잘못된 생각이었다.
우선, 하나의 adversarial example에 의해 여러 모델이 잘못 동작했고, 심지어 서로 같은 클래스로 misclassification을 수행했다. 따라서 학습 과정에서 model별 boundary가 복잡하기 때문에 생긴 random 오류라고 볼 수 없었다.
즉, 시스템 자체의 문제인 것이었다.
Underfitting
이에 연구자들은 이러한 문제가 오히려 지나치게 linear한 classifier, underfitting에 의한 것이 아닐까 생각하게 되었다.
실제로 deep nets는 부분적인 linear 형태를 지닌다고 밝혀졌다.
Input과 output 사이의 mapping이 piecewise linear한 형태인 것이지, 모델의 parameters와 output은 복잡한 non-linear 형태이다.
따라서 adversarial examples를 생성하는 것은 간단하다.
이미지는 거의 보이지 않지만 plot을 중점적으로 보면, automobile class의 image에 어떠한 direction vector* $ \epsilon$ 값을 더해주며 각 class에 대한 logits를 plot한 결과이다.
여기에서 더해진 direction이 frog class로의 direction이며, logits가 linear하게 변경되는 것을 확인할 수 있다.
FGSM
이러한 direction을 찾는 것은 어렵지 않다. 미분값의 sign을 찾고, gradient ascent algorithm을 이용하면 된다.
CIFAR 10 dataset에 FGSM을 이용해 방향을 찾고, $ \epsilon$ * direction을 더해가며 실험해본 결과이다.
(y축은 direction에 orthogonal한 vector)
각 grid는 서로 다른 test data를 의미하고, 흰색은 맞게 classification한 경우, 색칠된 영역은 다른 class로 prediction한 경우이다.
FGSM을 찾은 방향으로 이동하면 linear한 misclassification boundary가 발생하는 것을 확인할 수 있다.
반면 orthogonal한 방향으로는 발생하지 않는다.
- Problem, Attack
당연히 모델을 속이는 이러한 adversarial examples는 문제가 된다.
대표적으로 RL agent를 생각해보면, 주어진 영상을 보고 행동을 결정하는데 주어진 영상이 adversarial examples라면 잘못된 행동을 결정하게 되는 것이다.
그러나 그러한 경우를 막기위해 model 자체의 parameters를 숨기더라도, 해당 모델을 공격하는 adversarial examples를 생성하는 것은 어렵지 않다.
해당 모델에 대한 미분을 수행할 수 없더라도(FGSM 적용 불가), 그 모델이 어떻게 classification을 수행하는지만 mimick 하도록 학습한 모델(FGSM 적용 가능)을 이용해 찾은 adversarial examples는 traget model도 속일 확률이 매우 크다.
특히 여기에 ensembles 알고리즘까지 적용하여 여러 모델을 한 번에 mimicking하면 그 확률은 매우 커진다.
- Defense
먼저 아쉽게도 대부분의 defense는 성공하지 않았다고 한다.
(※ 17년도 강의이므로 현재는 더 다양한 defense 기법들이 나왔을 것으로 생각됩니다.)
Generative Modeling
데이터의 분포를 학습하는 generative modeling도 하나의 방법이 될 수 있다. 이미지가 정상적인 분포를 갖는지 아닌지 검사하는 것이다.
그러나 단순히 이미지에 대한 분포보다는 class를 먼저 예측하고, 해당 class에 대한 inputs의 분포가 더 중요한 것으로 나타나서, 단순한 generative modeling으로는 충분히 방어가 되지 않는다고 한다.
매우 정교하게 설계된 generative modeling이 어느 정도 효과가 있을 것이라고 발표자는 예측하고 있다.
애초에 adversarial examples를 통해 training을 진행하는 것이 그나마 동작하는 방법이다.
그래프를 보면 정상적으로 동작하는 것을 확인할 수 있고, regularization 효과로 인해 약간의 성능 개선도 확인할 수 있다.
(SVM이나 linear regression 같은 linear models는 어차피 그 경계가 linear하기 때문에 adversarial training이 덜 동작한다. 따라서 deep learning이 오히려 더 secure하다고도 볼 수 있다.)
from einops import rearrange
class Embedding(nn.Module) :
def __init__(self, input_size = 32, input_channel = 3, hidden_size = 8*8*3, patch_size = 4) :
super().__init__()
self.patch_size = patch_size
self.hidden_size = hidden_size
self.projection = nn.Linear((patch_size**2)*input_channel, hidden_size, bias = False)
self.cls_token = nn.Parameter(torch.zeros(hidden_size), requires_grad= True)
num_patches = int((input_size / patch_size) ** 2 + 1)
self.positional = nn.Parameter(torch.zeros((num_patches, hidden_size), requires_grad= True))
def forward(self, x) :
x = rearrange(x, 'b c (h p1) (w p2) -> b (h w) (c p1 p2)', p1 = self.patch_size, p2 = self.patch_size)
x = self.projection(x)
batch_size = x.shape[0]
x = torch.concat((self.cls_token.expand(batch_size, 1, self.hidden_size), x), axis = 1)
x = x + self.positional
return x
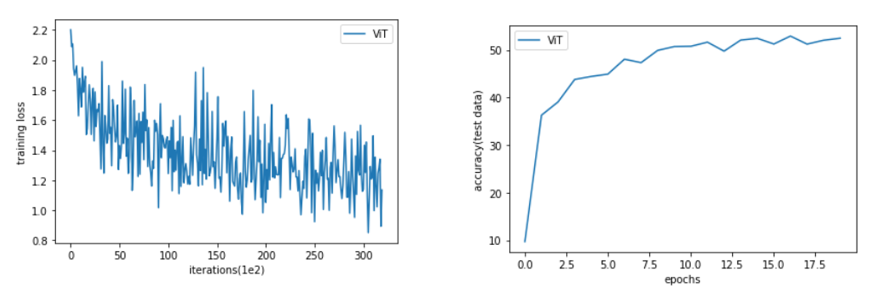
먼저 CIFAR 10 dataset은 3x32x32 크기로 작기 때문에, patch size와 hidden size 또한 그에 맞춰 작게 설정했습니다.
이미지를 patch로 나누는 과정이 복잡할 것이라고 예상했는데, 'einops'를 사용하면 한 줄로 간단하게 구현할 수 있었습니다.
Einops 동작
Input으로 주어진 images의 shape가 'batch size x channel x H x W'라고 할 때 H와 W를 각각 h, w개의 patch들로 이뤄졌다고 보고, 각각의 batch 별로 h*w 개의 c*p1*p2 크기의 vector로 만들라는 내용의 코드입니다.
Einops 자체가 직관적이라 arange로 표현된 예시와 함께 살펴보시면 이해될 것이고,
자세한 einops의 동작에 대해서는 공식문서나 튜토리얼이 있으니 찾아보면 좋을 것 같습니다.
원하던대로 image의 각 영역(patches)을 vector로 만든 것을 확인할 수 있습니다.
Cls token이나 positional embedding은 nn.Parameter를 통해 구현했고,
cls token의 경우 expand와 concat을 통해, positional embedding의 경우 broadcasting을 통해 더해줍니다.
여기에서도 einop의 rearrange와 torch.einsum을 이용하는데, 먼저 코드는 다음과 같습니다.
# https://github.com/FrancescoSaverioZuppichini/ViT/blob/main/transfomer.md
class MSA(nn.Module) :
def __init__(self, hidden_dim = 8*8*3, num_heads = 6) :
super().__init__()
self.num_heads = num_heads
self.D_h = (hidden_dim / num_heads) ** (1/2)
self.queries = nn.Linear(hidden_dim, hidden_dim)
self.keys = nn.Linear(hidden_dim, hidden_dim)
self.values = nn.Linear(hidden_dim, hidden_dim)
self.softmax = nn.Softmax(dim = 1)
def forward(self, x) :
q = rearrange(self.queries(x), 'b n (h d) -> b h n d', h = self.num_heads)
k = rearrange(self.queries(x), 'b n (h d) -> b h n d', h = self.num_heads)
v = rearrange(self.queries(x), 'b n (h d) -> b h n d', h = self.num_heads)
A = torch.einsum('bhqd, bhkd -> bhqk', q, k)
A = self.softmax(A / self.D_h)
Ax = torch.einsum('bhan, bhnd -> bhad' ,A, v) # b : batch size, h : num_heads, n : num_patches, a : num_patches, d : D_h
return rearrange(Ax, 'b h n d -> b n (h d)')
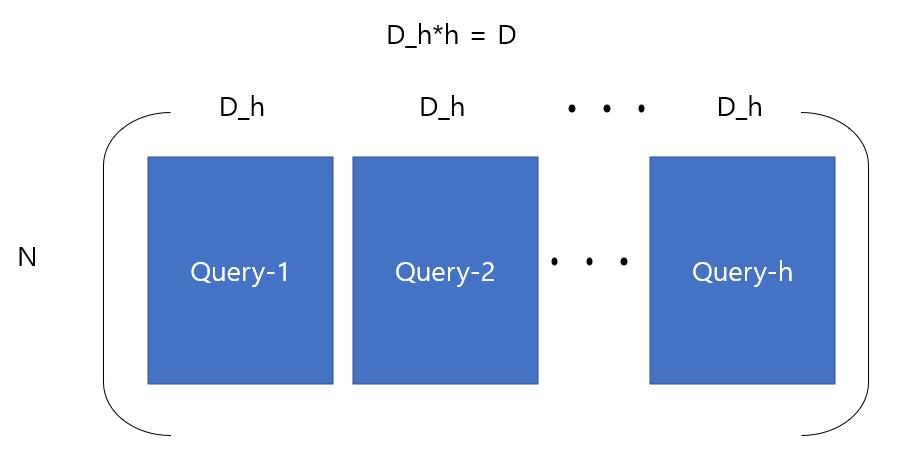
먼저 query, key, value weights를 nn.Linear layer로 선언하는데, 이번엔 모든 heads의 weights를 하나의 layer로 처리하기 때문에 output의 크기로 D(hidden dim)가 유지됩니다.
즉, 각 헤드별로 Nx$ D_h$, (N x D) x (D x $ D_h$)의 결과를 생성하는 것을 한번에 N x D로 처리합니다.
따라서 forward weight를 거친 결과는 다음과 같게 됩니다.(query 기준, h : # of heads)
따라서 먼저 einops의 rearrange를 통해 shape를 변형해줍니다.
'b n (h d) -> b h n d'로 변환되는 과정은 아래와 같습니다. 각 head별 output으로 분리해줍니다.
(batch size = 2, num patches = 4, hidden_dim = 2, num_heads = 3인 경우의 예시입니다.)
rearrange
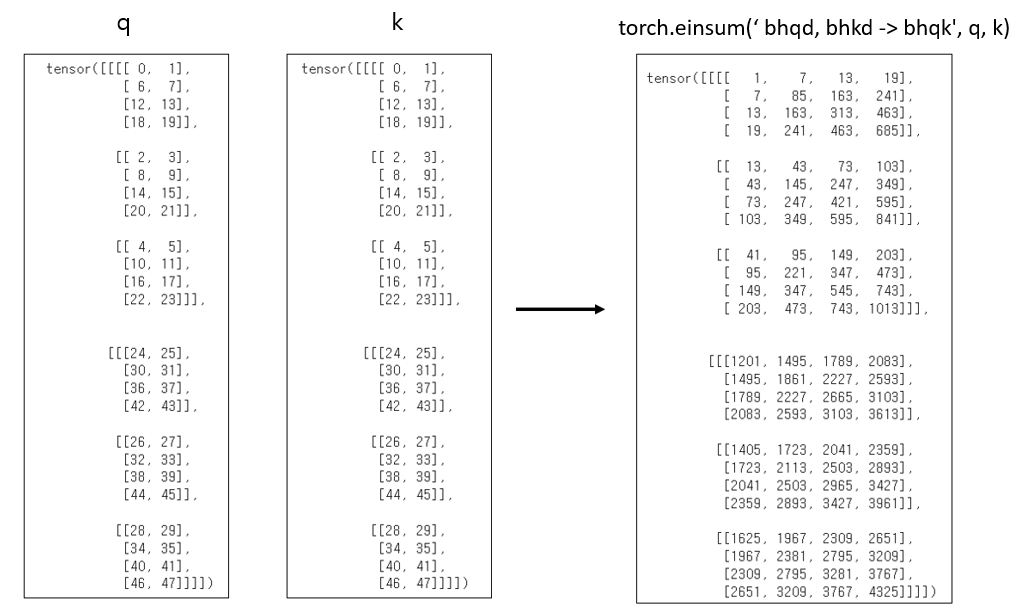
이제 einsum을 이용해서 분리된 shape에 맞게 $ QK^T$를 계산해줍니다.
('bhqd, bhkd -> bhqk', q, k)를 수행하게 되면 위와 같이 batch나 head구조는 유지되면서 각 head별로 $QK^T$가 계산됩니다.
사실 einsum을 이번에 처음 접해봐서 정확한 동작은 모르겠지만, ('bhqd, bhkd -> bhqk', q, k)를 수행하게 되면 위와 같이 shape에 맞춰서 k의 값들이 자동으로 transpose된 후 곱해지는 것으로 보입니다.
(Transpose가 이뤄진 후 곱해지는 것은 확실하지 않지만 우선 결과는 그렇게 생각했을 때와 동일합니다.)
그 결과 Batch x # heads x N x N shape의 결과가 나오는 것을 확인할 수 있고, 여기에서 다시 einsum을 이용해서 각 batch, head 별로 $ Av$를 계산해줍니다.(A = softmax($ \frac{QK^T}{\sqrt{D_h}}$))
마찬가지로 batch나 head 별 구조는 유지하면서 NxN 크기의 attention weight와 Nx$D_h$ 크기의 value matrix를 곱해주면 되므로 'bhan, bhnd -> bhad'와 같이 변경되도록 작성해줍니다.
(attention weight를 bhnn이 아니라 bhan으로 표현한 이유는 nn과 같이 하나의 문자로 두개의 차원을 표현하면 안되기 때문입니다.)
그 결과 Batch x # heads x N x $D_h$ 크기의 결과가 나오므로, 마지막으로 다시 rearrange를 사용해서
Batch x N x D(= # heads * $D_h$)의 shape으로 변경시켜줍니다.
rearrange(Ax, 'b h n d -> b n (h d)')와 같이 변경시켜주면 됩니다.